O objetivo deste documento é a padronização das nomenclaturas observando regras geralmente aceitas no meio em que se insere a Defensoria Pública de Minas Gerais e visando as integrações necessárias às suas atividades, notadamente aquelas a serem estabelecidas junto a outros órgãos do Governo, seja no Executivo ou no Judiciário, não descartando o Legislativo.
O padrão utilizado como base é o referencial do Datasus datado de julho de 2018 em consonância com a norma ISO/IETEC 11179-5 e padrões de interoperabilidade do Governo Federal seguidos por este documento.
Casos omissos neste documento deverão ser sanados pelo documento citado acima ou em comum acordo com a Superintendência de Tecnologia da Informação da Defensoria Pública de Minas Gerais.
O nome do objeto deve apresentar clareza, de forma a indicar a sua finalidade no negócio a que está vinculado. Não deve ferir a norma culta da língua portuguesa.
O nome de um objeto de banco de dados deverá ser formado por uma ou mais palavras com todas as letras em maiúsculas e no singular, cada uma
separada pelo caractere separador underscore (_). A sequência das palavras deve ser lógica de tal forma que dê um significado preciso em Português.
Para a formação de cada palavra de um nome, deve-se sempre considerar a portabilidade entre SGBD´s, sendo assim utilize apenas os caracteres alfabéticos não acentuados e numéricos.
Para o caso de abreviações, as seguintes regras devem ser observadas:
Palavras em outro idioma não serão permitidas.
As exceções deverão ser tratadas caso a caso.
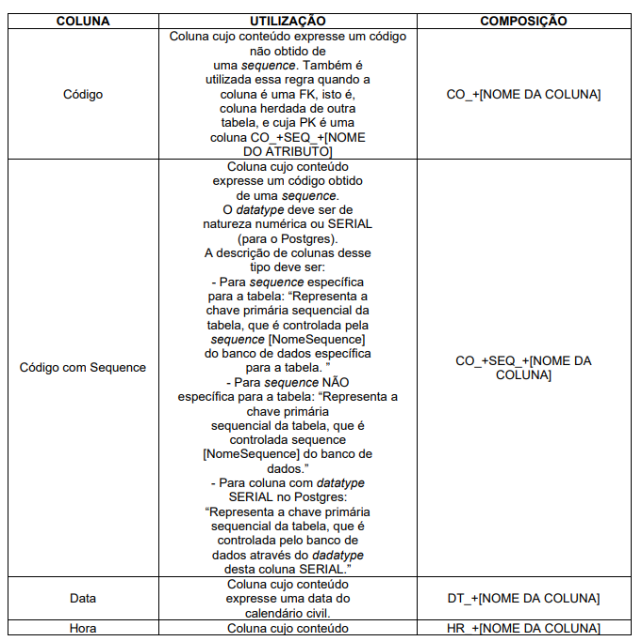
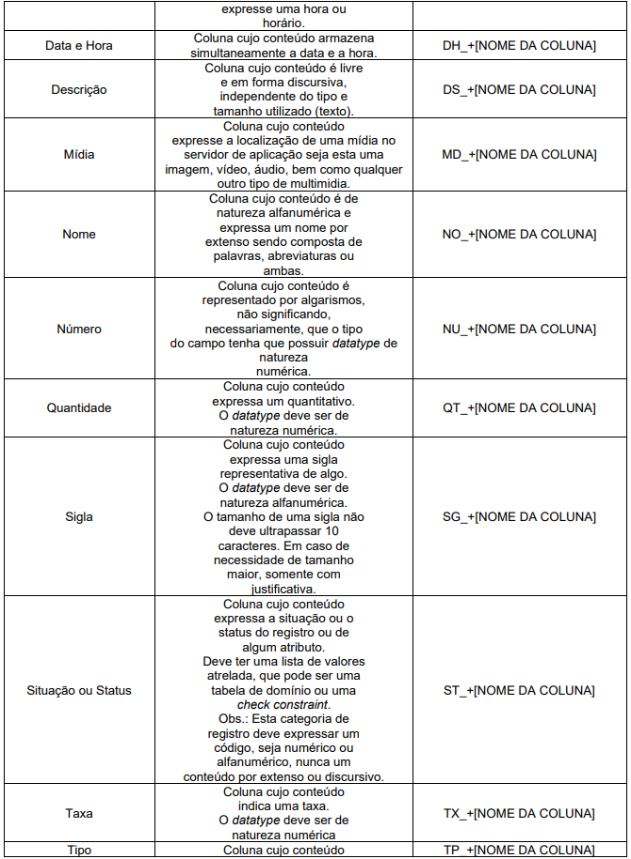
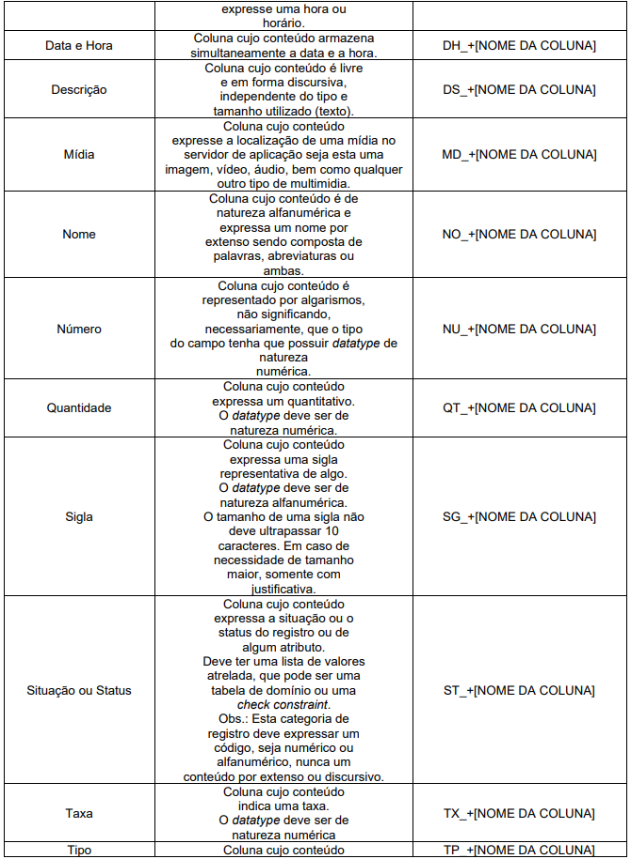
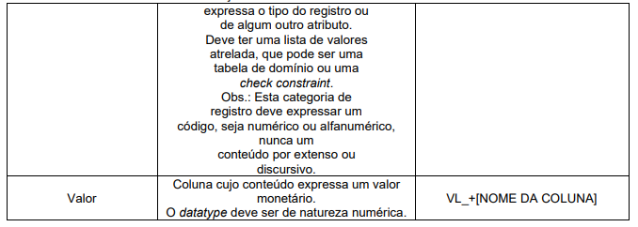
Nome de qualquer tipo de objeto e colunas de tabelas deve possuir a formação Prefixo_NomeObjeto.
O prefixo para o caso de tabelas e colunas define uma categorização para cada um, sendo que no caso de colunas não é indicado tipo e tamanho que deve estar associado, pois isso depende do negócio, mas é importante observar o bom senso nesse tipo de definição, por exemplo, para colunas cujo tamanho é de informações conhecidas como CPF ou CNPJ deve-se utilizar o tipo e tamanho de acordo com a definição existente, sendo CPF com varchar2(11) e CNPJ com varchar2(14). Para os casos onde o domínio está definido em tabela, deve-se utilizar esta como FK
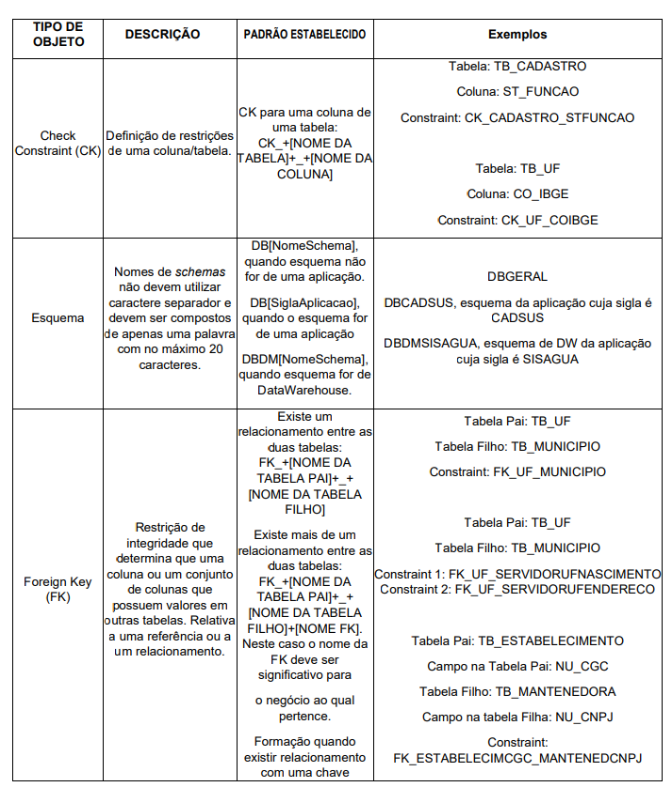
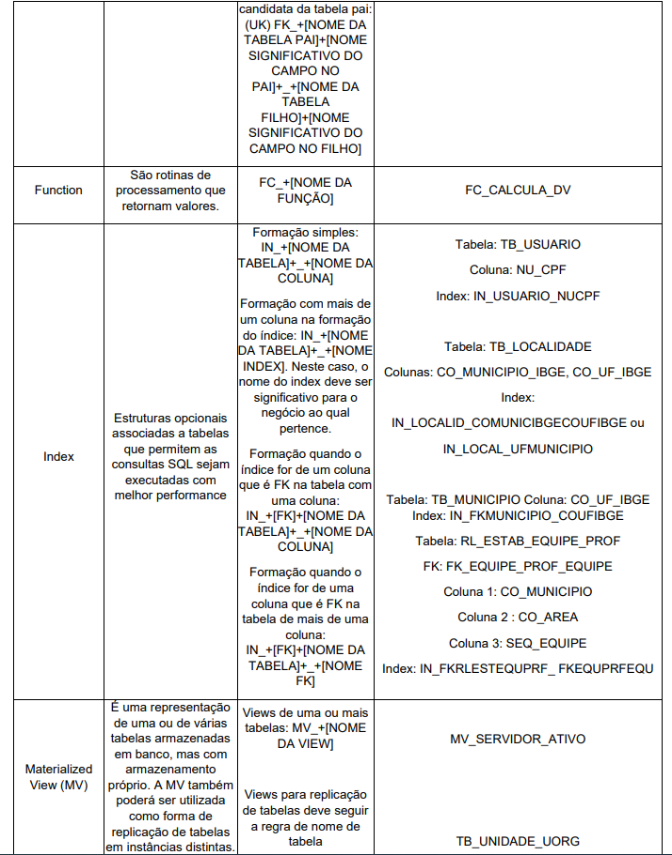
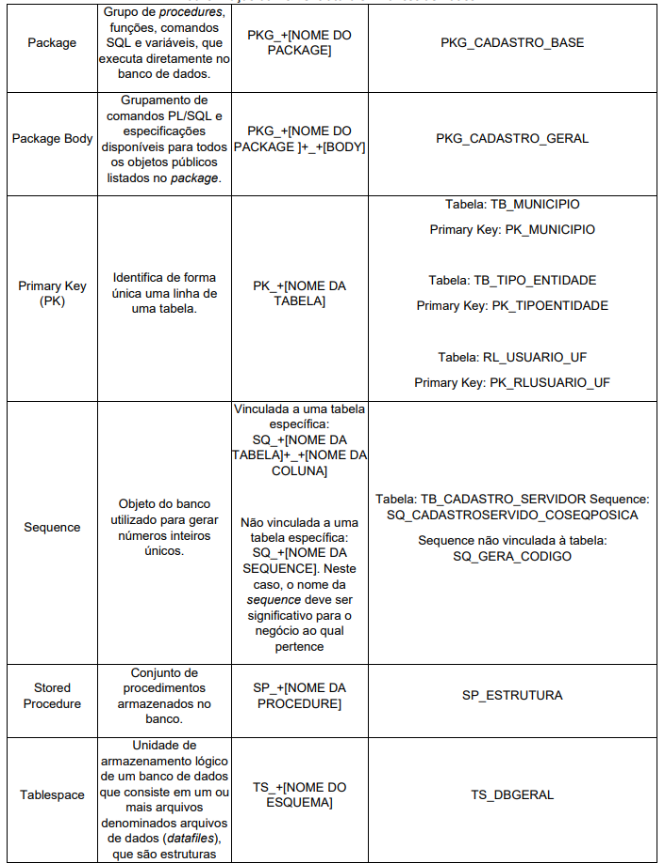
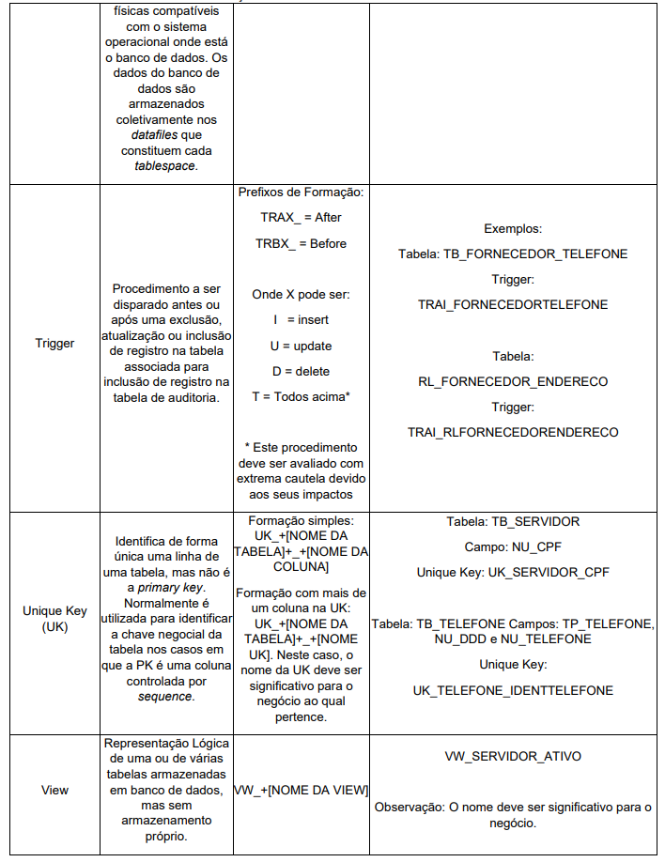
O prefixo de cada objeto deve indicar a finalidade do mesmo, conforme definido no Anexo I.
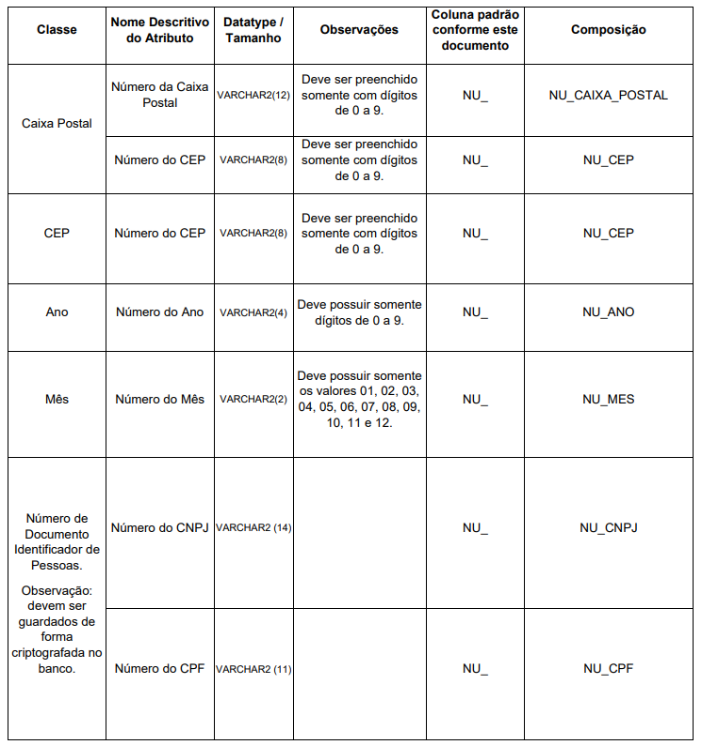
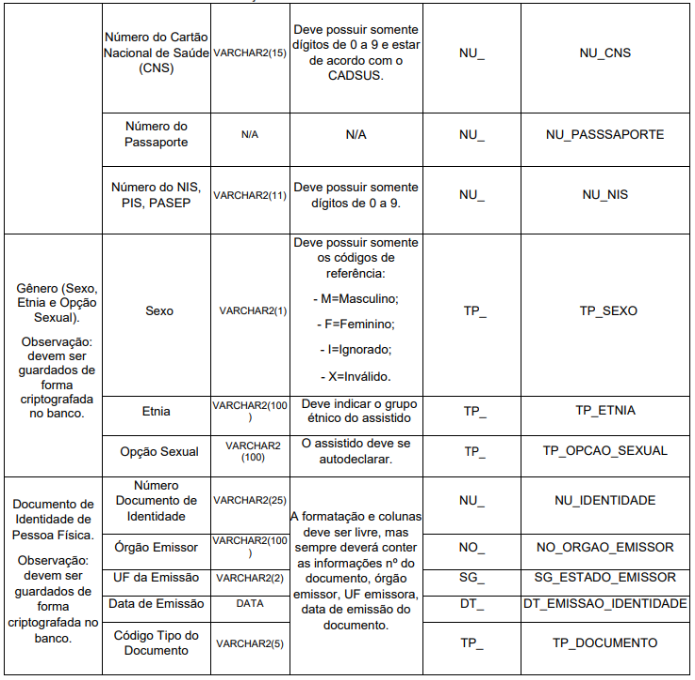
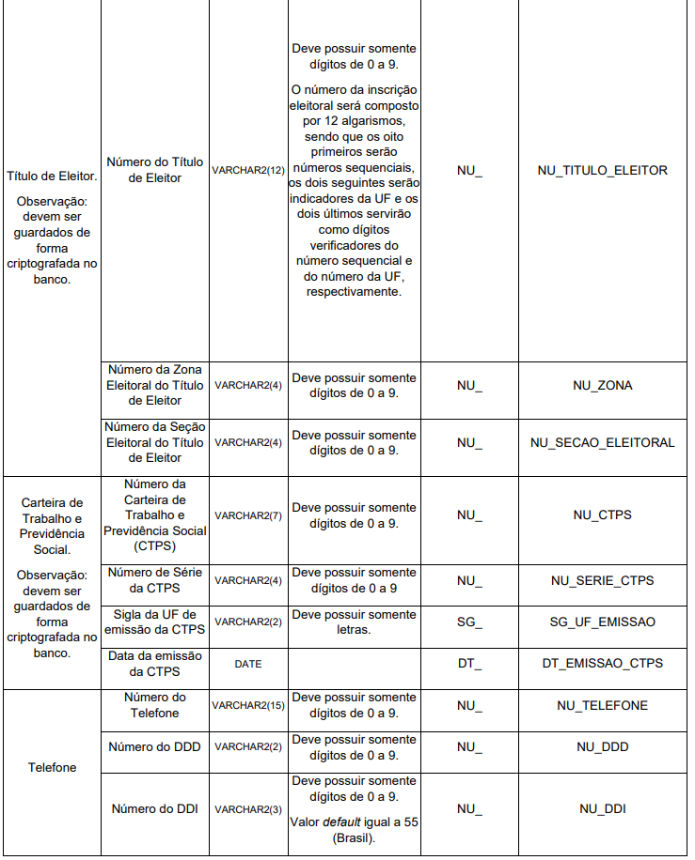
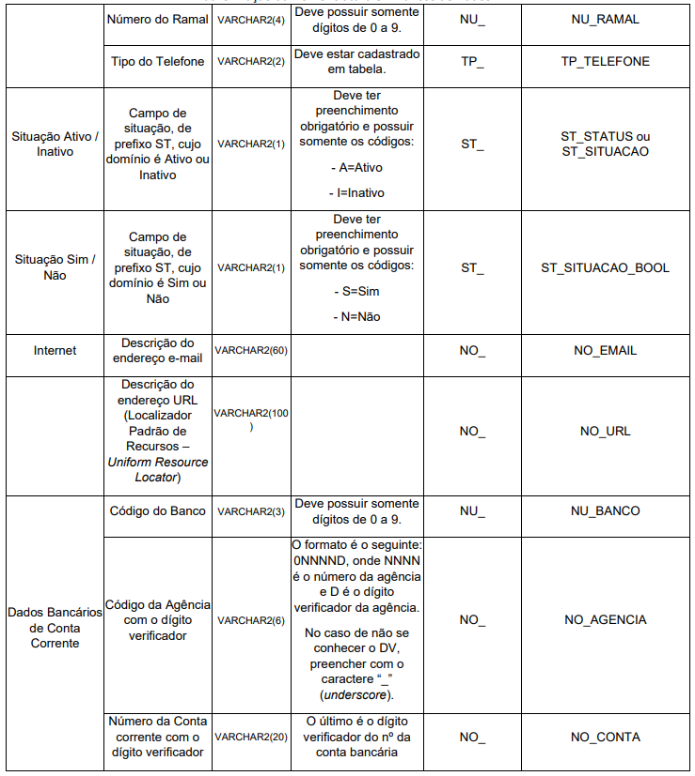
Para informações comumente utilizadas e que o conjunto dos atributos contidos em cada classe compõe uma informação foi definido no Anexo II “Classe de Dados”. Exemplos: CPF, telefone, carteira de trabalho, etc. As informações contidas nesse anexo, devem seguir as regras lá definidas.
Para o caso de exclusão lógica de registro em uma tabela o tratamento deve ser o seguinte:
a) Deve ter um campo com nome ST_REGISTRO_ATIVO datatype VARCHAR2(1) e domínio S ou N;
b) A sua descrição pode ser “Indica se o registro está ativo ou não (excluído logicamente). O seu domínio é: S – Sim (está ativo) ou N – Não (não está ativo). O controle no uso de registros excluídos deve ser feito pela aplicação.”;
c) Quando a tabela é criada já com essa coluna, não é obrigatório a definição de um valor DEFAULT, mas quando a coluna é adicionada em uma tabela já existente, deve- se definir o valor DEFAULT, pois assim a coluna pode ser criada como NOT NULL e o valor DEFAULT será preenchido para todos os registros existentes na tabela.
Para o caso de necessidade de exclusão física de registros deve ser informada a necessidade de auditoria ou não. No caso de não necessidade é preciso autorização do gestor.
O tamanho máximo de um nome de objeto não pode exceder 30 caracteres.
No caso de o nome do objeto ultrapassar o tamanho máximo estipulado, a seguinte regra deve ser utilizada:
No Anexo I, tabela 1, onde são tratados os prefixos dos objetos, as seguintes
regras devem ser consideradas para as referências indicadas a seguir:
Para abreviação de palavras contidas nos nomes de objetos deve preferencialmente utilizar a regra definida no documento “Governo Brasileiro – Comitê Executivo de Governo Eletrônico – Catálogo de Padrões de Dados”. As regras contidas nesse documento são as seguintes:
sempre que possível, evitar o uso de abreviaturas/acrônimos, pois prejudicam o entendimento;
a) Abreviaturas comumente usadas em português a abreviaturas de negócio;
b) Abreviaturas de negócio à termos de tecnologia da informação;
c) Termos da tecnologia da informação à criação de novos;
d) Criar abreviaturas evitando ambiguidade.
A Superintendência de Tecnologia da Informação, através da Diretoria de Desenvolvimento em Sistemas e Projetos, validará e acompanhará o uso destas normas por terceiros e por servidores.
Observações:
| TIPO DE TABELA | DESCRIÇÃO | TIPO DE TABELA DE NEGÓCIO (SIM/NÃO) | PADRÃO ESTABELECIDO |
| Tabela de Sistema | Tabela utilizada para armazenar dados de aplicação | sim | TB_+[NOME DA TABELA] |
| Tabela de Relacionamento (Associativa) | Tabela que resolve relacionamentos “N para N” entre duas tabelas. | sim | RL_+[NOME DA TABELA1]+_+[NOME DA TABELA2] |
| Tabela Log de Operações | Tabela utilizada para armazenar dos dados das operações de usuários realizadas no esquema. Exemplos de operações: insert, update, delete. Este tipo de tabela somente pode ser utilizado para log’s alimentados cuja responsabilidade é da equipe de desenvolvimento de sistemas | Não | TL_+[NOME DA TABELA] |
| Tabela Temporária | Tabela utilizada em rotinas dos sistemas para armazenamento temporário de dados. | sim | TM_+[NOME DA TABELA] |
| Tabela de Histórico | Tabela utilizada para armazenar os dados históricos de uma determinada funcionalidade, podendo ter vida útil para os dados. | sim | TH_+[NOME DA TABELA] |
| Tabela de Relacionamento Ternário (Associativa) | Tabela que resolve relacionamentos “N para N”, envolvendo três tabelas ou mais | sim | RT_+[NOME DA TABELA] |
| Tabela do Robô | Tabela utilizada em rotinas automatizadas do sistema. | sim | RB_+[NOME DA TABELA |
Observações:
Observações:
A Superintendência de Tecnologia da Informação, realiza a partir das colunas de auditoria um rastreio de onde, quando e quem realizou qualquer alteração nos dados daquela tabela.
Periodicamente os dados destas colunas são coletados e organizados para apresentações, na prestação de contas e identificação do usuário responsável.
As tabelas são padronizadas com as seguintes colunas, utilizando os atalhos do (ITEM 7- PADRÕES PARA COLUNAS):