O “Documento Arquitetural de Software da DPMG” possui como finalidade definir os conceitos a serem aplicados no processo de desenvolvimento de sistemas da instituição. Reunir todas as informações necessárias para concluir as atividades demandadas, através de uma visão macroscópica em termos de componentes que interagem entre si.
Estão contemplados neste documento informações de tecnologias de desenvolvimento (backend e frontend) e também tecnologias de implantação dos produtos finais (configuração e mudança) através de um fluxo já pré-definido de entregas condizentes à testes e produção, obrigatoriamente através de controle de versões (repositórios) para facilitar a rastreabilidade.
É também escopo deste documento, a orientação aos colaboradores sobre os padrões de desenvolvimento definidos pela DPMG além das suas respectivas definições de projetos. Serão descritas as camadas que compõe a arquitetura da instituição, requisitos de desempenho e segurança da informação.
A definição de bancos de dados utilizados nos projetos será explicada no decorrer deste documento, assim como os servidores de aplicação dos mesmos. Serão relatadas ferramentas de monitoramento de aplicações e servidores, com o intuito de ajudar na análise de erros e prever possíveis “problemas” futuros agindo de forma antecipada.
Baseado na escalabilidade necessária para melhor funcionamento dos sistemas da DPMG, de forma integrada, foi definido a utilização do JAVA e toda sua stack para implementações de aplicações robustas.
Java é uma linguagem de programação e plataforma computacional lançada pela pela Sun Microsystems em 1995. Existem muitas aplicações cujo funcionamento estão condicionados à presença do Java instalado. Java é uma linguagem gratuita, está entre as linguagens mundialmente mais usadas e atualmente é mantida pela Oracle.
Principais características do Java:
Os sistemas comunicam entre si através de “cliente-servidor”, onde as aplicações frontends (cliente) realizam requisições na API Gateway (servidor) para manipulações e consultas de dados. As API’s são responsáveis por receber as request de microsserviços, validar o acesso aos endpoints via permissão do usuário, manipular o dado e retornar a informação solicitada via response.
Os microsserviços possuem definições a serem seguidas, como por exemplo a implementação de rollbacks em todos os métodos que utilize transação. Também deverão ser serviços simples e objetivos. Todos os endpoints devem ser documentados através do Swagger e com o SCSDP corretamente configurado.
Sempre com o pensamento de utilização de tecnologias atuais do mercado, foi definido o framework Vue.js (versão 2 e 3) para as implementações referentes ao Frontend dos sistemas. Vue possui uma comunidade nova, porém já bem extensa e colaborativa, facilitando assim o desenvolvimento das soluções.
Vue JS é um framework progressivo utilizado para a construção de interfaces de usuário. O framework Vue foi projetado desde o início para ser adotável incrementalmente. A biblioteca principal é direcionada exclusivamente na camada visual (view layer), sendo fácil adotar e integrar com outras bibliotecas ou projetos existentes. Por outro lado, Vue também é capaz de dar poder a sofisticadas Single-Page Applications quando usado em conjunto com ferramentas modernas e bibliotecas de apoio.
O framework Vue também oferece suporte à linguagem typescript que é um sistema de tipagem estática e pode ajudar a prevenir muitos erros potenciais em tempo de execução, especialmente conforme as aplicações vão crescendo.
O Vue possui como principais características:
A linguagem padrão definida pela DPMG para o frontend é o TypeScript, por motivo de tornar mais fácil a identificação de erros no código deixando assim a manutenalibidade futura mais simples. Por ser uma linguagem que permite a tipagem das variáveis, é possível perceber falhas durante o processo de desenvolvimento. O TypeScript não interfere na transpilação do código a ser lido por todas versões de browser, como geralmente é feito com o Babel em aplicações JavaScript.
Para versões do Vue 3 foi adotado o método de Composition API. Utilizamos pre-processador Sass mais especificamente Scss para facilitar e melhorar sintaxe CSS, a ideia é manter a lógica do CSS (seletores, regras etc), mas de uma maneira mais organizada, intuitiva e com trechos de código facilmente reutilizáveis.
O Quasar foi o framework de componentes e sistema de grid escolhido para criação das telas dos sistemas vue versões 2, visto que oferece uma vasta gama de opções já disponíveis em seu catálogo, além de ser nativo do Vue, ele também é baseado no Material Design e seus ícones.
As telas devem ser padronizadas de acordo com sistemas anteriores, ou com aceitação do demandante, obedecendo as regras definidas na paleta de cor da Defensoria Pública de Minas Gerais. Os sistemas devem ser gerenciados pelo roteador nativo que se integra na instância do Vue. As rotas obrigatoriamente precisam estar corretamente configuradas com o SCSDP.
O desenvolvimento conta também com a opção de controles de estados utilizando o Vuex, deixando centralizado o armazenamento dos estados para todos as telas do sistema. Para Versões do Vue 3 foi escolhido o Pinia por indicação da documentação do próprio vuex (https://vuex.vuejs.org/)
A linguagem para o desenvolvimento de aplicações mobile é Dart, pelo fato da DPMG ter escolhido o Flutter, que é um kit de ferramentas de UI da Google para criação de aplicativos nativamente compilados para Android e iOS a partir de uma única base de código, tornando assim a manutenção mais eficaz e produtiva.
“Flutter é um kit de ferramentas do Google para construir aplicações lindas, nativamente compiladas para mobile, web, desktop a partir de um único código-base.”(FLUTTER, 2021)
Em mais detalhes o Flutter é um framework desenvolvido pelo Google na linguagem Dart para a criação de aplicativos multiplataforma, web, mobile e desktop. Diferentemente de outras soluções, como Ionic e React Native, o Flutter não é executado em uma WebView (Ionic) e nem utiliza componentes nativos através de uma “ponte” (DEVMEDIA, 2021). Ao invés disso gera código verdadeiramente nativo, tanto para Android quanto para iOS.
O Dart é uma linguagem de cliente otimizada (Dart VM) utilizada para o desenvolvimento de aplicações rápidas em qualquer plataforma. Seu objetivo é oferecer uma linguagem de programação mais produtiva para o desenvolvimento multiplataforma, associado à uma plataforma de execução flexível para frameworks de aplicação. A tecnologia de compilação do Dart possibilita a execução do código em diferentes meios:
Plataforma Nativa
Para aplicações direcionadas para dispositivos mobile e desktop, o Dart inclue tanto a Dart VM com compilação just-in-time (JIT) e um compilador ahead-of-time (AOT) para geração do código de máquina.
Plataforma Web
Para aplicações direcionadas para a web, o Dart inclui tanto o compilador development time (dartdevc) e o compilador production time (dart2js). Ambos os compiladores traduzem o Dart em JavaScript.
Um dos principais diferenciais do Flutter é a rapidez de desenvolvimento, visto que possui um rico conjunto de widgets totalmente personalizáveis e de fácil utilização através da sua arquitetura em camadas, resultando em uma renderização rápida.
Introdução
A escolha do WordPress como plataforma baseia-se na sua facilidade de uso, rapidez de desenvolvimento e flexibilidade na gestão de conteúdos.
WordPress
O WordPress é uma ferramenta gratuita e open-source, desenvolvida em PHP, amplamente utilizada para criação de blogs e portais. Suas principais vantagens incluem:
PHP
PHP (Hypertext Preprocessor) é uma linguagem de script open-source, altamente adequada para o desenvolvimento web e embutível em HTML. Suas principais características incluem:
Definição de Objetivos
Facilitar a Gestão de Conteúdos
Utilizar o WordPress para facilitar a gestão de conteúdos, permitindo a publicação de notícias, artigos e outras pautas da instituição.
Desenvolvimento Ágil
Aproveitar as capacidades do WordPress para permitir um desenvolvimento rápido e flexível, possibilitando a gestão de conteúdos a qualquer momento e lugar.
Estrutura
Padrões de Desenvolvimento de Temas
A estrutura do portal deve ser compatível com a criação de temas para WordPress, seguindo rigorosamente os padrões estabelecidos. Isso inclui:
Documentação
Requisitos Funcionais e Não-Funcionais
Documentar todos os requisitos funcionais e não-funcionais do projeto para garantir clareza no escopo e expectativas.
Especificações Técnicas
Elaborar especificações técnicas detalhadas, incluindo:
Manuais de Usuário
Criar manuais de usuário para administradores e gestores de conteúdo, explicando o uso eficiente das funcionalidades do WordPress.
Tecnologias Utilizadas no Frontend
Utilização de JavaScript Vanilla para consumir APIs REST, garantindo simplicidade e eficiência na comunicação com microserviços.
Plugins
Segurança e Compatibilidade
Plugins de terceiros não são utilizados para evitar problemas de segurança e incompatibilidades futuras.
Análise e Possibilidades
Caso algum plugin seja necessário, deve-se abrir um chamado interno detalhando a necessidade e os benefícios esperados para solicitar um plugin específico.
Todos os chamados são analisados pela equipe de desenvolvimento para avaliar a viabilidade técnica e a segurança antes da aprovação.
Desenvolvimento de Plugins
O plugin será desenvolvido, seguindo padrões de codificação, segurança e integração com o sistema existente.
Documentação e Testes
Cada plugin deve ser bem documentado e passar por testes rigorosos para garantir funcionalidade e integração sem problemas com outros componentes do sistema.
Arquitetura e Integração com Microserviços
Cada serviço é responsável por uma funcionalidade específica, facilitando a escalabilidade e manutenção do sistema.
APIs
Utilizar APIs REST em JSON para comunicação entre os microserviços, frontend e backend, garantindo interação eficiente e flexível.
Arquivos
Utilizar servidor de arquivos ( file server ) para fazer uploads e downloads através da API.
Autenticação e Autorização
Implementar mecanismos robustos de autenticação e autorização para proteger a comunicação entre os serviços e garantir a segurança dos dados.
Segurança
Utilizar a segurança do sistema *Gerais para liberar acesso a administração e autenticar envio dos arquivos ao file server.
Manutenção e Suporte
Atualizações Regulares
Manter todos os componentes do sistema atualizados, incluindo WordPress, plugins e dependências de microserviços.
Sistema de Suporte Interno
Estabelecer um sistema de suporte interno para resolver rapidamente quaisquer problemas, garantindo a continuidade e eficiência das operações.
Monitoramento Contínuo
Implementar ferramentas de monitoramento para acompanhar a performance do sistema e identificar possíveis problemas em tempo real, permitindo uma resposta rápida e eficaz.
Os testes automatizados buscam garantir a qualidade e padrão das aplicações, seguindo as regras de negócio e os protótipos determinados. Para tanto, o Selenium Java foi escolhido para tal finalidade por possuir uma vasta quantidade de recursos que permitem automações robustas.
O Selenium Java é uma ferramenta utilizada no java que permite acessar e navegar por páginas web de forma automatizada, parametrizada e que permite verificar existência e funcionalidade de elementos nas páginas.
Um grande diferencial do Selenium Java é a possibilidade de integração com o Jenkins via maven, além de executar os testes em paralelo, reduzindo consideravelmente o tempo de execução.
Baseado em organização dos códigos para garantir melhor leitura e manutenção de serviços, foi definido uma arquitetura de forma que seus módulos possuam baixo acoplamento entre si e de fácil compreensão, permitindo um desenvolvimento ágil.
A arquitetura base é composta por 1 projeto “pai” que agrupa 4 projetos “filhos”. Estes 4 projetos são definidos como módulos, e eles são separados em: Dependencies, Migration, Persistence e Service. Em casos específicos em que o projeto tenha automações, poderá ser incluído os módulos Job e Shared.
O Módulo de Dependencies tem como objetivo gerenciar as bibliotecas que os demais módulos poderão utilizar.
O Módulo Migration é responsável pela gestão dos scripts de banco de dados que deverão ser executados para o correto funcionamento do módulo Persistence. Os scripts são organizados em pasta de estrutura e pasta de dados. Os dados devem ser separados por ambiente (Desenvolvimento, Homologação e Produção).
O Módulo Persistence é responsável pelas classes Java de mapeamento objeto relacional das tabelas e seus relacionamentos. Por fim, e não menos importante, existe o módulo Service, que contém todo o fluxo de desenvolvimento das regras de negócio da aplicação. É neste módulo que devem ser criados as Controllers (para serviços REST), os DTOs (para objetos JSON), os EJB’s (para codificações das regras de negócio), os DAOs (para persistir ou buscar no banco de dados).
O Módulo Job possibilita o agendamento de tarefas, as quais serão executadas em horários pré-definidos.
O Módulo Shared tem como objetivo evitar que o Módulo Job tenha que fazer uma integração para acessar a serviços remotos dentro do projeto.
Os projetos Frontend’s da instituição DPMG deve seguir o Style Guide do Vue.Js por default. Sendo isso, eles devem ter separações dos seus arquivos por objetivo em diretórios: models, utils, controllers, router, service, store e views. Vale ressaltar que é possível, e recomendado, a criação de subdiretórios para organização da feature.
Todos os arquivos referentes à algum POJO ou Model devem ficar na pasta de models, assim como todos os arquivos para consumo de API via serviços devem ficar na pasta controllers/services. Tudo que for útil para várias telas devem estar na pasta de utils. O arquivo de definições do Vuetify/Quasar fica na pasta de controllers/plugins, assim como a configuração de outros plugins, caso tenha. As rotas devem ser definidas e configuradas no arquivo base (index.ts) do diretório router, separados por suas hooks.
O Vuex/Pinia possui uma pasta separada, com o nome de store, em que é organizado em pastas distintas por módulos. As telas informadas nas rotas devem estar na pasta de views e caso alguma parte da tela seja utilizada em vários lugares, deve ser criado um componente genérico com funcionamento independente. O arquivo deste componente deve estar no diretório: views/components.
Obedecendo os princípios recomendados pelo Style Guide do Vue.js, as definições de nomes de variáveis, classes e arquivos de extensão .vue devem seguir o padrão de CamelCase/SnackCase. Importante ressaltar que nomes de classes e de arquivos devem ser iniciados com letra maiúscula.
Para o Vue.js v3.* e utilizamos para criação de formulários o vee-validate em conjunto com Pinia sendo suas regras definidas utilizando o Yup.
Para trabalhar com aplicativos, devemos ter em mente alguns princípios de Clean Code para melhorar a qualidade do seu código, como por exemplo: obedecer ao padrão de desenvolvimento (Design Pattern) e seguir a estrutura do projeto (arquitetura). Com isso a instituição definiu separações dos arquivos em pacotes apesar de que a flexibilidade é a marca registrada do Flutter.
A organização do projeto se dá a partir da pasta lib, que geralmente terá apenas o arquivo main (executa o projeto com as propriedades de um determinado ambiente) e uma pasta de src (source), nela teremos os demais arquivos Dart.
No desenvolvimento de aplicativos adotamos a estrutura de pastas usando o padrão BLoC. Os BLoC’s são criados para separar regras de negócio da interface de usuário, algo recomendado em diversas tecnologias, baseado em fluxos que podem ser observados de qualquer tela e parte do seu código
Ainda sobre a organização de pastas do projeto, deve ser separado por features (funcionalidades) em que dentro de cada uma fique todos os seus respectivos arquivos codificados, dentro de diretórios: services, models e screens (onde ficam as screen, os blocs, as actions, os states e os listeners). As telas são compostas por screens que acionam states (o layout em si).
O state da tela faz utilização do BLoC da feature, que consequentemente trabalha em conjunto com as actions e seus respectivos states e listeners para realizar uma ação final.
Neste tópico abordaremos padrões definidos pela instituição DPMG que devem ser seguidos no decorrer das implementações das aplicações demandadas, sejam elas no backend, frontend ou mobile. É importante ressaltar a necessidade disso para tornar mais eficiente a sustentação dos códigos produzidos, além de garantir maior segurança para os servidores da Defensoria Pública de Minas Gerais.
Para criar o projeto: Execute o comando na pasta onde deseja criar o projeto.
mvn archetype:generate -DarchetypeGroupId=br.def.mg.defensoria – DarchetypeArtifactId=archetype-backend -DarchetypeVersion=2.1.9 -Dprojeto=nome-projeto
Ps: Caso o settings do Maven não esteja na pasta padrão deverá adicionar o seguinte atributo-s /diretorio/arquivoSettings.xml
Ao gerar esse comando será gerado um projeto maven multi-modules com a camada de persistência e serviço, um módulo de dependências também será gerado com as dependências mais utilizadas nos projetos.
O projeto gerado será montado com a seguinte Stack de tecnologias:
As configurações de charset e encode já serão realizadas. O pacote de todos os modulos já definidos por padrão com o seguinte valor: br.def.mg.defensoria.nomeProjeto O groupId é definido pelo padrão da defensoria:br.def.mg.defensoria
Observação: O pacote default gerado deve ser alterado caso o nome do projeto seja composto, alterando para nome.projeto não é possível automatizar essa parte trocando “-” por “.”
Classe utilitária utilizada para a realização de requisições HTTP.
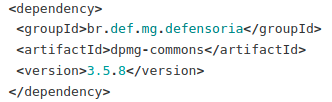
Para a realização de requisições do tipo GET retornando um objeto Java:
Onde:


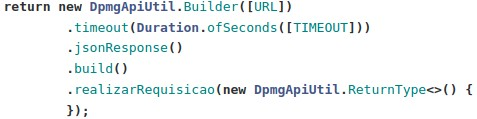
Para adicionar query parâmetro:

Para ignorar a resposta:


Onde:

Para retornar uma resposta do tipo text/plain :

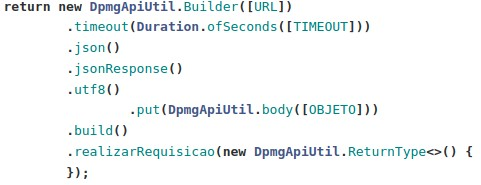
Onde:

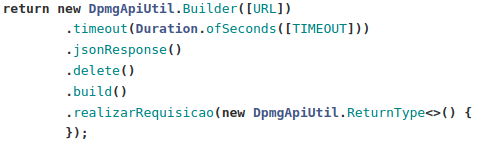
Onde:


Onde:
É importante que os layouts, botões, fontes e ícones estejam de acordo com a Paleta de Cor da DPMG.

Partes de telas que serão utilizadas em mais de um lugar, deverão ser componentizadas, para tornar a manutenibilidade mais eficaz.
Conforme mencionado no item 4.1.1 todos os microsserviços dos projetos obrigatoriamente devem estar com seus acessos configurados através de perfis do SCSDP. Para isso, o projeto tem que possuir a dependência do SCSDP e assim conseguir realizar interceptações das requisições.
Assim como no backend, é necessário também realizar a configuração no frontend para realizar interceptações das requisições nas rotas, impedindo assim o acesso indevido às funcionalidades dos projetos.
Para iniciar uma evolução arquitetural, melhoria e/ou correção, o desenvolvedor deve criar uma branch a partir da branch “dev” conforme padrão citado no item 5.1. Após a conclusão, o código deve ser disponibilizado na branch “dev”. Com isso, automaticamente será disparado uma execução de deploy no ambiente de desenvolvimento.
Após conclusão do deploy no ambiente de desenvolvimento deve ser realizada uma validação básica do produto entregue. Não havendo erros/falhas o desenvolvedor em questão pode promover as alterações para o ambiente de teste “tst” através de MR (Merge Request). Além disso o código deve atender as regras do SonarQube.
Quando é encontrada alguma falha na entrega realizada, o testador registra uma issue e a atribui ao desenvolvedor responsável pela entrega. Para realizar a correção, o desenvolvedor deve criar uma branch a partir da branch “dev”, conforme o padrão citado no item 5.1. Após a correção, o fluxo retorna ao passo 5.3.
Após a validação em ambiente de teste, o líder técnico da DDSP deve promover as alterações para o ambiente de homologação, com o objetivo de realizar a homologação do produto com a área demandante.
Após homologação com a área demandante (cliente), as alterações (evolução arquitetura, melhorias ou correções) seguem para o processo de delivery em ambiente de produção através do líder técnico da DDSP.
5.6 – FLUXO DE HOTFIX
Quando é identificado a necessidade de uma correção imediata diretamente em ambiente de produção, deve-se obrigatoriamente criar uma branch de hotfix a partir da branch “prod” onde será executada a correção. Após a conclusão, deve-se disponibilizar na branch “prod” a correção através de MR. A branch deve seguir o padrão de criação definido no item 5.1.
Neste tópico iremos abordar ferramentas e configurações dos projetos, ensinando o colaborador a instalar e utilizar conforme necessidade da demanda. Os prints de exemplos contidos aqui podem vir a ser diferente da versão da ferramenta utilizada pelo profissional no futuro.
IntelliJ IDEA é um ambiente de desenvolvimento integrado (IDE) para linguagens JVM, desenvolvida para maximizar a produtividade do desenvolvimento. Ele faz a rotina e as tarefas repetitivas para você, fornecendo uma inteligente complementação de código, análise estática de código, refatoramentos, permitindo ao desenvolvedor manter o foco apenas no lado importante do desenvolvimento de software. IntelliJ IDEA foi desenvolvido como um IDE para linguagens JVM, mas diversos plugins pode extende-la para proporcionar uma experiência poliglota.
Linguagens JVM suportadas: Java, Kotlin, Scala, Groovy
Outras linguagens: Python, Ruby, PHP, SQL, Go, JavaScript, TypeScript, CoffeeScript, Thymeleaf, JSON, Markdown, HTML e XHTML, XML e XSL, XPath e XSLT, Velocity e FreeMarker, StyleSheet (CSS, Less, Sass), Dart, Erlang.
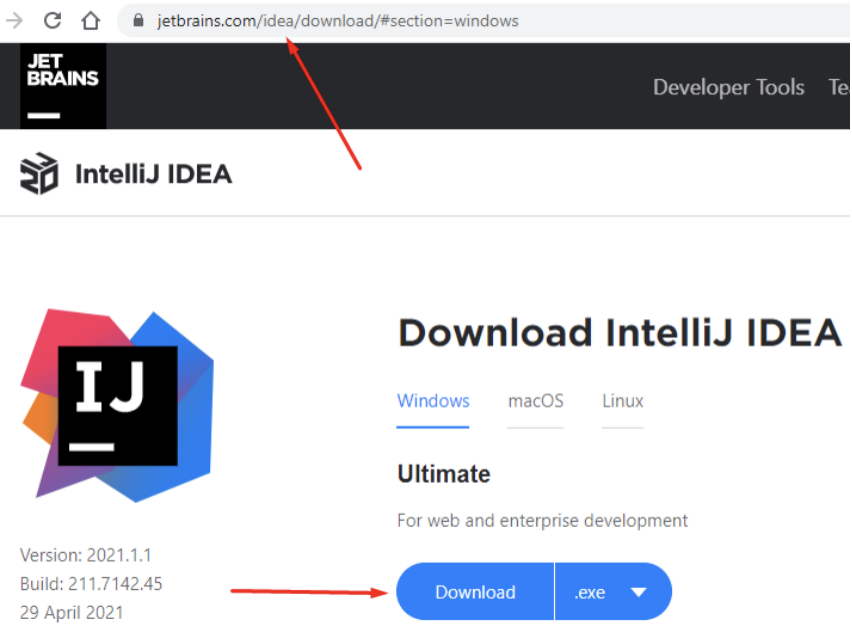
O Intellij é a IDE preferencial para codificação dos projetos (backend, frontend e mobile). Para utilização, o desenvolvedor deve acessar o site oficial do fabricante: (Jetbrains) https://www.jetbrains.com/idea/download/#section=windows. E realizar o download conforme o seu sistema operacional. (No exemplo abaixo foi utilizado o Windows)
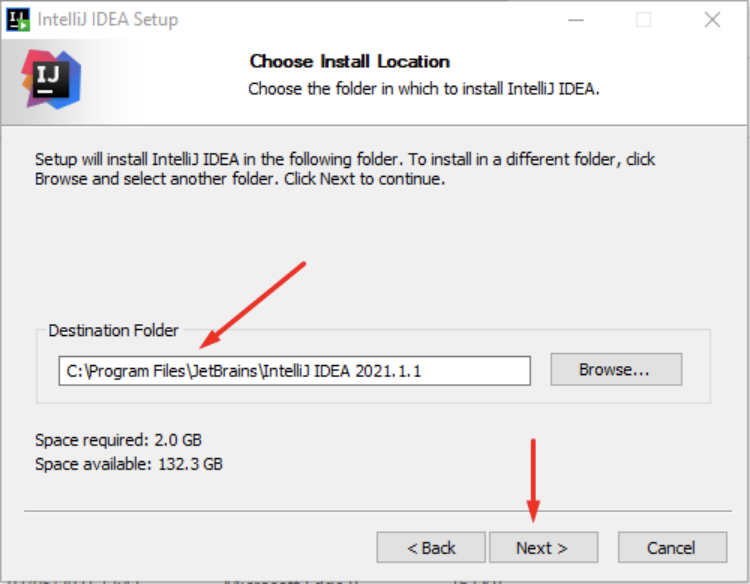
Após concluir o download da ferramenta, localize o arquivo e o execute. Nos passos da instalação deve ser definido o diretório da instalação e na sequência clique em “Next”:
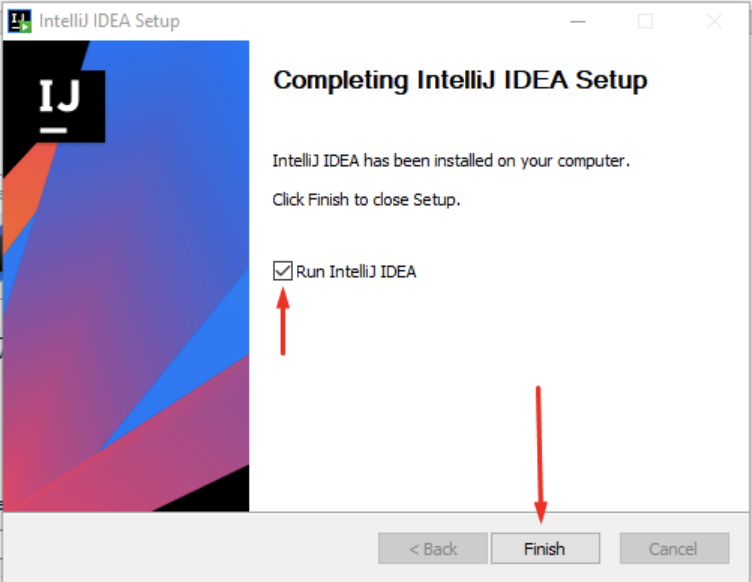
O processo de instalação desta ferramenta não possui nenhuma diferença das demais instalações convencionais. Após a conclusão da instalação clique para iniciar o programa e em seguida clique em “Finish”:
No fluxo de inicialização selecione o termo de aceite, e clique em “Continue”:
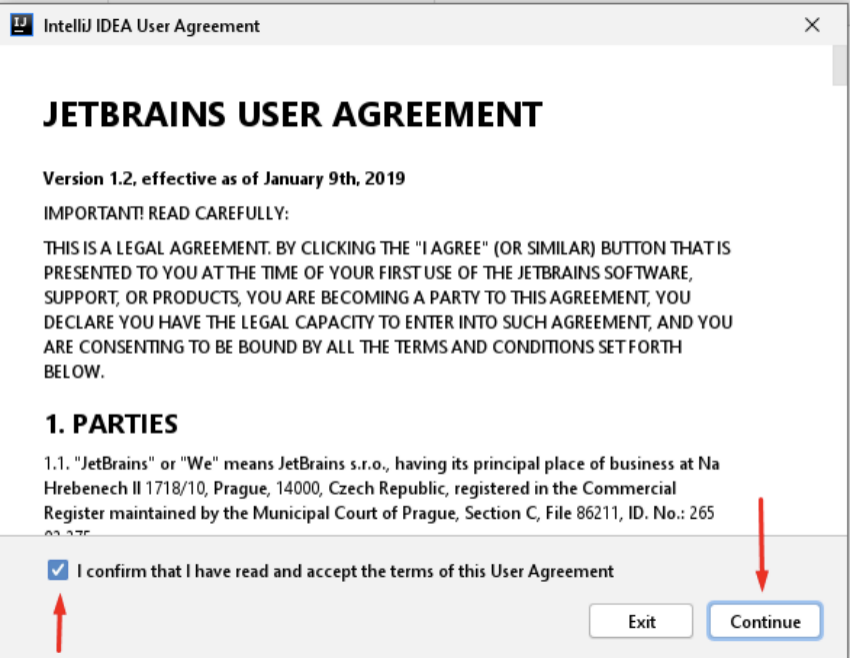
Com a ferramenta já em execução, deve-se realizar o login com a finalidade de ativar a licença fornecida pela instituição DPMG:
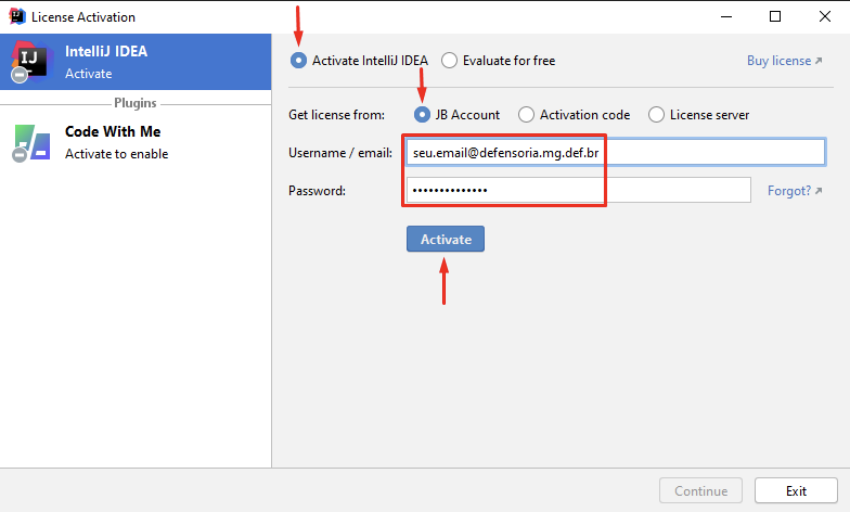
Com a ferramenta ativada, inicia-se a configuração global. Para isso, clique em “Customize” e em seguida “All Settings“
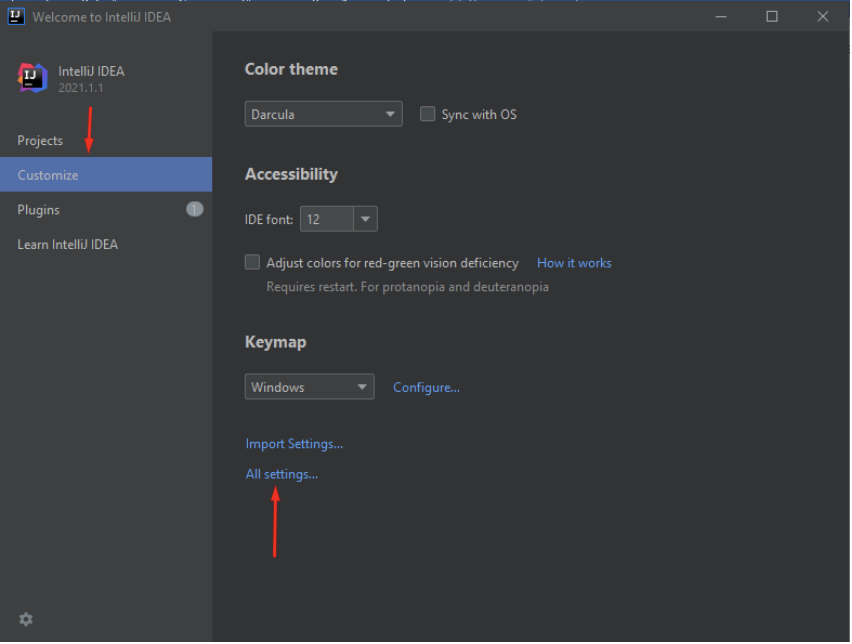
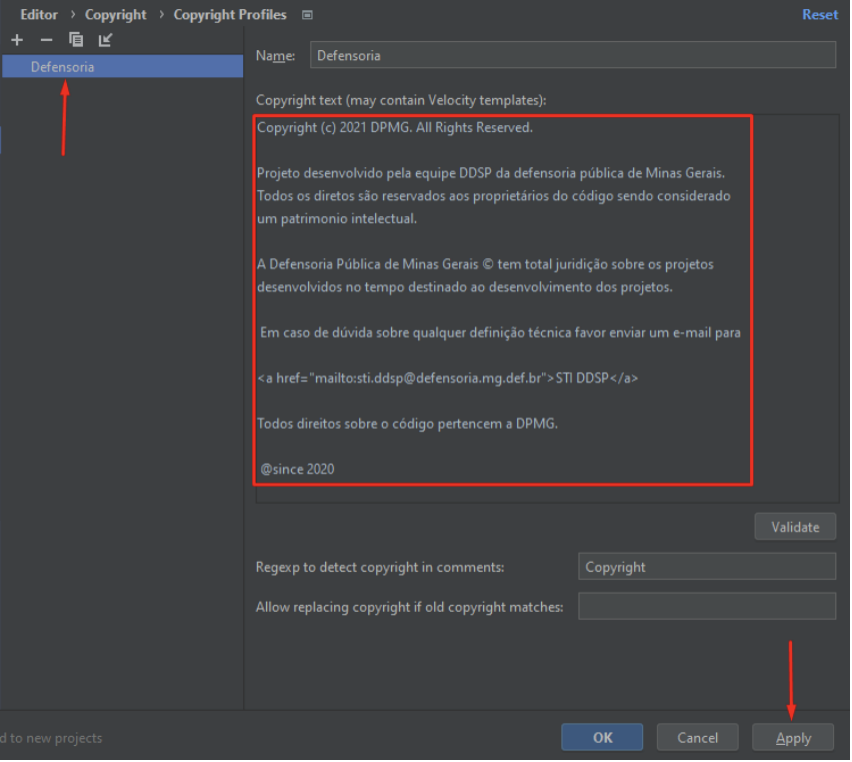
É necessário que a ferramenta esteja com o Copyright devidamente configurado, para isso, no campo de busca, localize a aba de “Copyright Profiles” e clique no ícone de Importar:
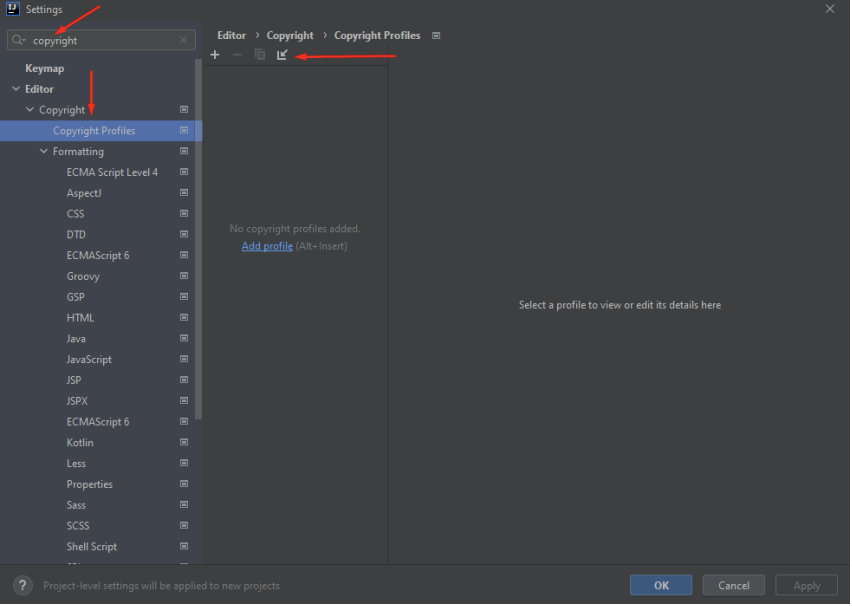
Localize no computador o arquivo de profile do Copyright fornecido pela instituição DPMG:
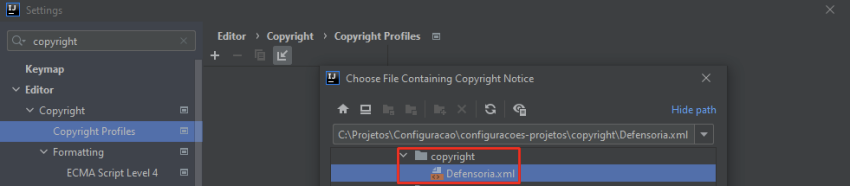
Se a tela estiver igual a evidência abaixo, significa que tudo ocorreu corretamente com a importação do profile de Copyright, clique em “Apply”:
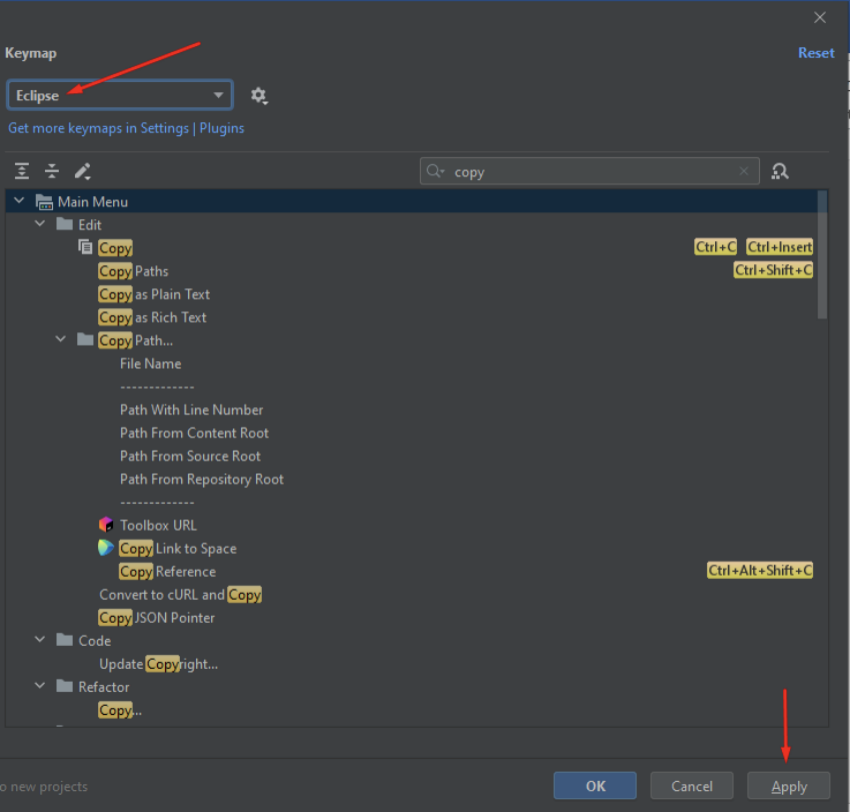
Para padronizar os atalhos de desenvolvimento mundialmente utilizados, deve-se a encontrar a aba de “Keymap” e suas opções:
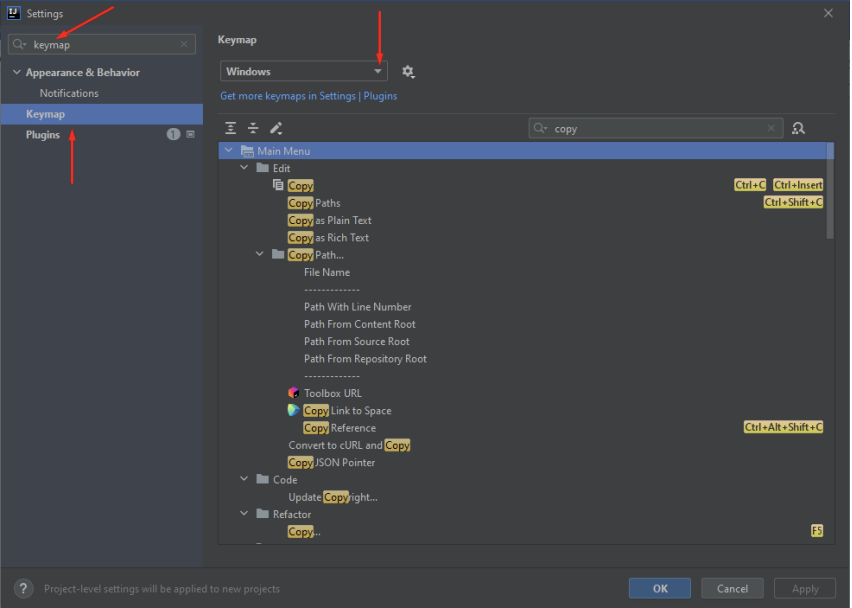
Selecione a opção Eclipse:
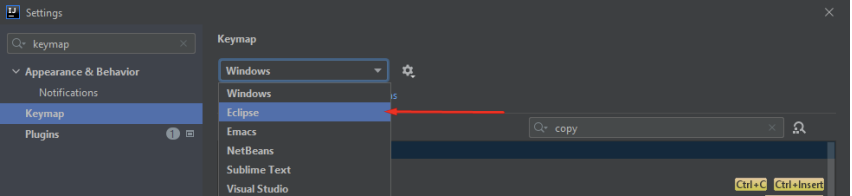
Se a tela estiver igual a evidência abaixo, significa que os principais atalhos de desenvolvimento durante utilização da ferramenta seguirá o padrão da IDE Eclipse, clique em “Apply”:
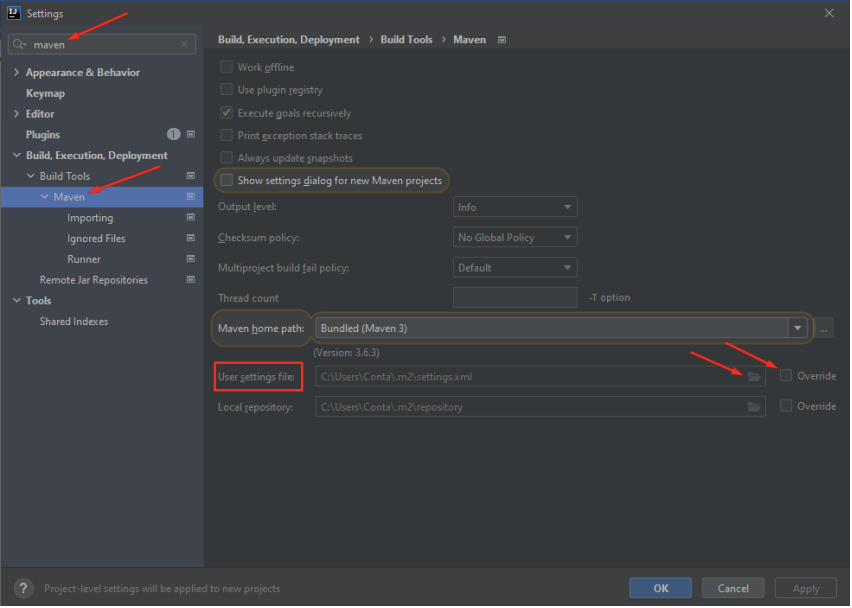
Para realizar download das dependências dos projetos que serão utilizados na ferramenta, é necessário que seja realizado o apontamento para o repositório Nexus da DPMG. Para isso, localize a aba “Maven”, localize a opção “User settings file”, clique em “Override” e em seguida no ícone, ao lado, de uma pasta:
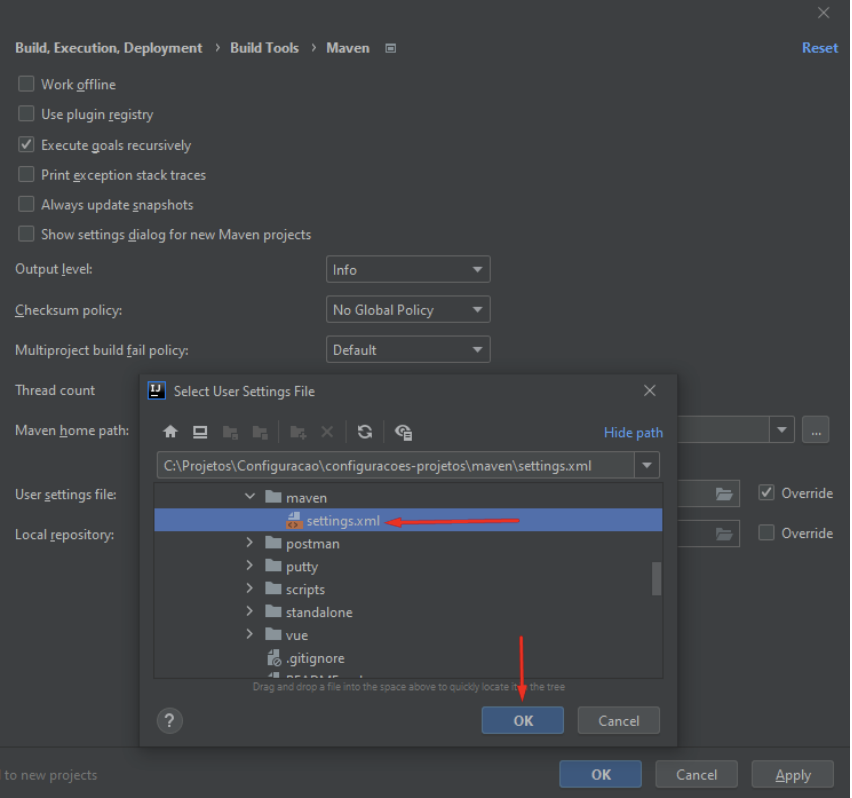
Localize na sua máquina o arquivo “settings.xml” fornecido pela instituição DPMG, que conterá os apontamentos necessários:
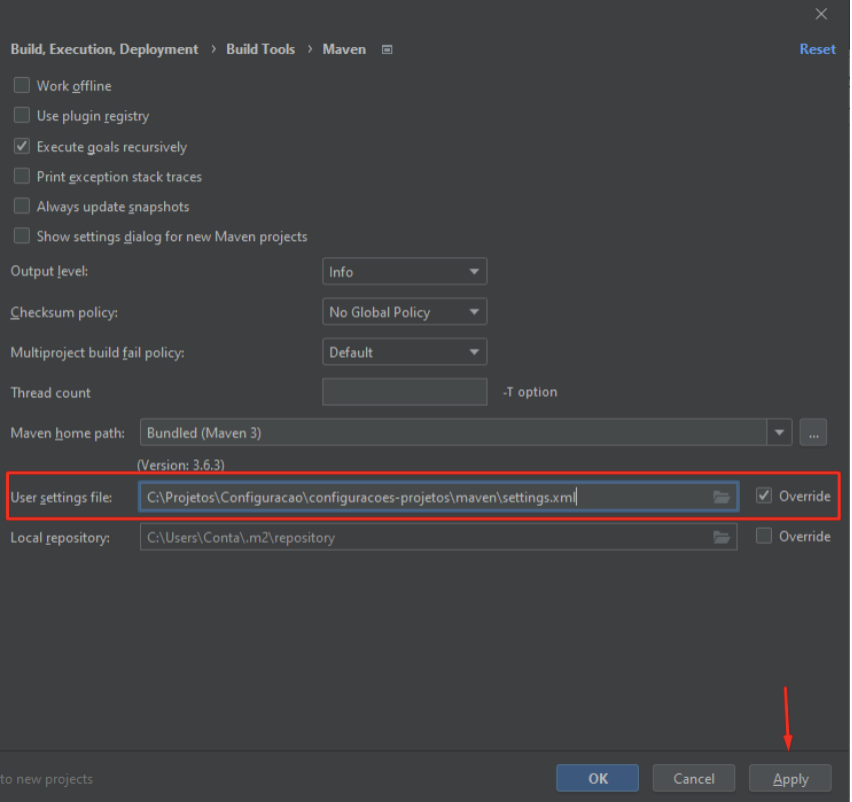
Com a opção de “Override” selecionada, e com o arquivo devidamente informado, clique em “Apply”:
Por fim, devemos realizar instalações de plugins úteis pra auxiliar o desenvolvimento, para isso localize a aba “Plugins”:
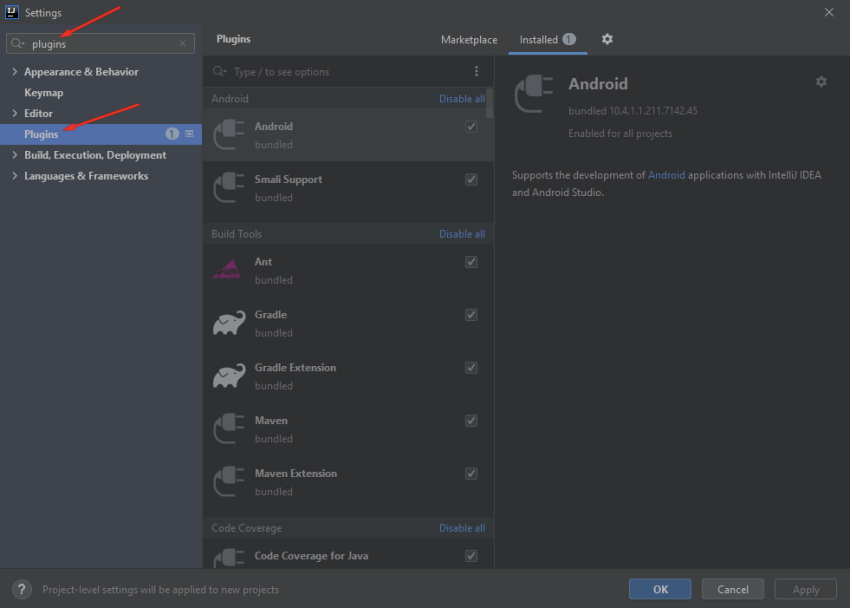
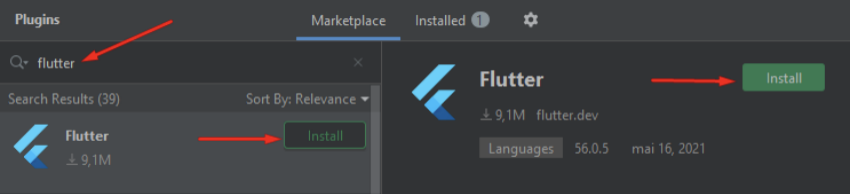
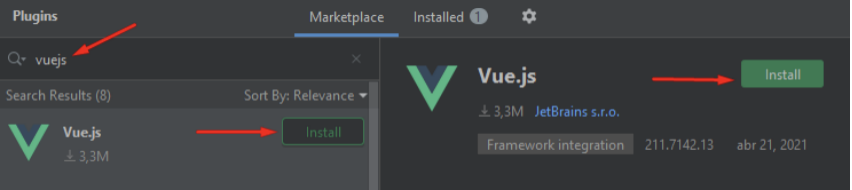
Faça a instalação dos seguintes plugins: Flutter, Dart e Vue.js:

Após a instalação do último plugin, clique em “OK”:
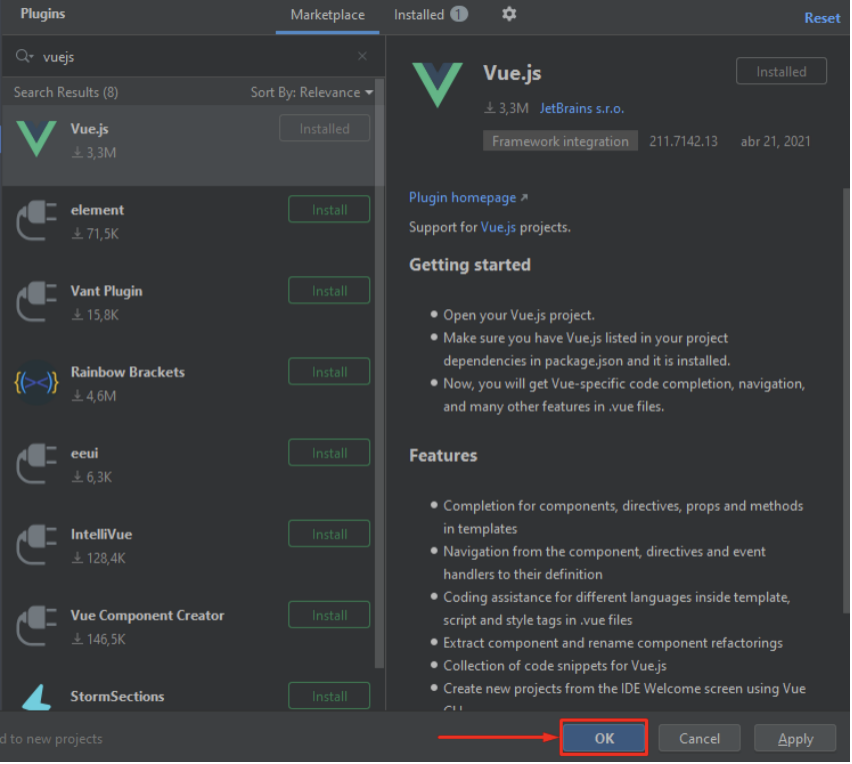
Com isso, a ferramenta Intellij estará devidamente configurada, e pode-se dar início à abertura do seu projeto Maven, clicando em “Projects” e em seguida, clicando em “Open”:
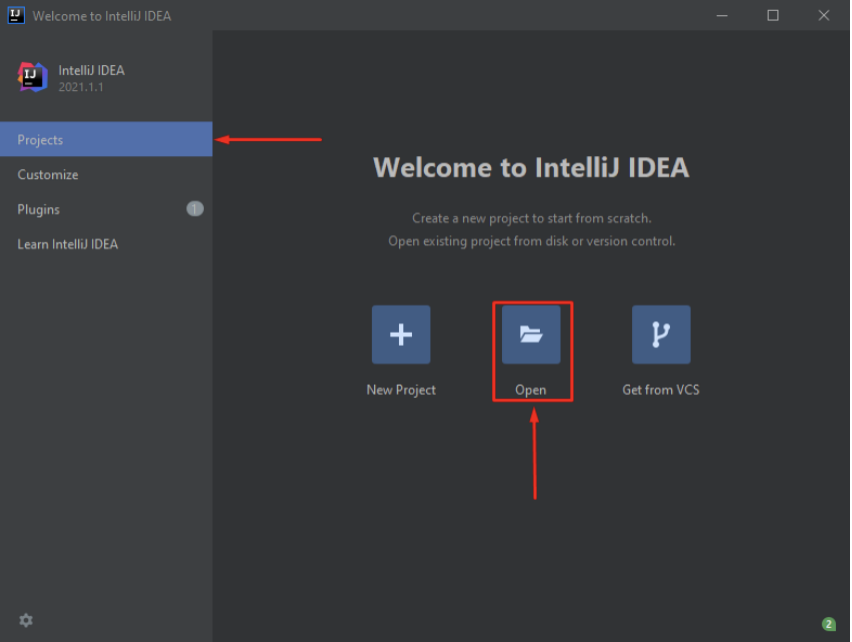
Visual Studio Code é um editor de código-fonte, leve porém poderoso, disponível para Windows, Linux e MacOS. Ele vem com suporte integrado para JavaScript, TypeScript e Node.js e tem um rico ecossistema de extensões para outras linguagens (como C ++, C #, Java, Python, PHP, Go) e tempos de execução (como .NET e Unity).
No Visual Studio Code, temos suporte para quase todas as principais linguagens de programação, como por exemplo, JavaScript, TypeScript, CSS e HTML, mas mais extensões de linguagem rica podem ser encontradas no VS Code Marketplace.
A plataforma Eclipse é fornecida com um ambiente de desenvolvimento integrado (IDE) Java completo. O conjunto de ferramentas de desenvolvimento Java (JDT) permite aos usuários escrever, compilar, testar, depurar e editar programas escritos na linguagem de programação Java, consequentemente contribuindo com a visualização, edição e ações específicas do Java para o ambiente de trabalho.
**Principais Ferramentas: **
O Xcode consiste em um conjunto de ferramentas que os desenvolvedores usam para construir aplicativos para as plataformas Apple. Usa-se o Xcode para gerenciar todo o fluxo de trabalho de desenvolvimento – desde a criação do seu aplicativo até o teste, a otimização e o envio para a App Store. Ele pode iniciar suas ferramentas de desenvolvimento ou você pode iniciá-las independentemente do menu Xcode.
Principais ferramentas:
Dbeaver é uma ferramenta de Banco de Dados gratuita, opensource, para desenvolvedores e administradores de banco de dados. A ferramenta é escrita em Java e baseada na plataforma Eclipse.
Principais características:
O MySQL foi criado na Suécia por suecos e um finlandês: David Axmark, Allan Larsson e Michael “Monty” Widenius, que têm trabalhado juntos desde a década de 1980. Hoje seu desenvolvimento e manutenção empregam aproximadamente 400 profissionais no mundo inteiro, e mais de mil contribuem testando o software, integrando-o a outros produtos, e escrevendo a respeito dele.
O sucesso do MySQL deve-se em grande medida à fácil integração com o PHP incluído, quase que obrigatoriamente, nos pacotes de hospedagem de sites da Internet oferecidos atualmente. Sem entrar muito nos méritos técnicos, os principais processos e características que acontecem em um ambiente MySQL são os mesmos.
PostgreSQL é um sistema de gerenciador de banco de dados objeto relacional (SGBD), desenvolvido como um projeto open-source. O PostgreSQL foi o pioneiro em muitos conceitos que só se tornaram disponíveis em alguns sistemas de banco de dados comerciais muito mais tarde.
O PostgreSQL foi projetado para rodar em plataformas semelhantes ao Unix. No entanto, o PostgreSQL também foi projetado para ser portátil, para que pudesse ser executado em várias plataformas, como Mac OS X, Solaris e Windows. É fácil de manter devido a sua estabilidade. Portanto, se você desenvolver aplicações baseados no PostgreSQL, o custo de desenvolvimento será baixo em comparação com outros sistemas de gerenciamento de banco de dados.
O PostgreSQL é um descendente de código aberto do código original desenvolvido em Berkeley e suporta uma grande parte do padrão SQL e oferece muitas características modernas, como é o caso de chaves estrangeiras, functions, triggers, Views, integridades transacionais, data types, funções agregadas, operadores, dentre muitos outros. Ele consiste em um processo de servidor que lê e grava os arquivos de banco de dados reais, e um conjunto de programas cliente que se comunicam com o servidor. O mais comumente utilizado é o comando psql, que permite ao usuário executar consultas SQL e visualizar os seus resultados.
**O PostgreSQL oferece muitos recursos: **
De várias maneiras, o usuário ainda pode customizar adicionando novos:
Banco de dados NoSQL (“not only SQL”) são não tabulares e armazenam dados de forma diferente das tabelas relacionais, bancos de dados NoSQL vem com uma variedade de tipos baseada no seu modelo de dados. Os principais tipos são documentos, chave-valor, coluna ampla e grafo. Eles provêm esquemas flexíveis e escalam facilmente com grandes porções de dados e altas cargas de usuários.
MongoDB é o banco de dados orientado a documentos, projetado para o desenvolvimento de aplicações modernas, está disponível como software para download e também na forma de um banco de dados como serviço (DBaaS) totalmente gerenciado. A grande característica de Banco de Dados Orientados a Documentos é possuir todas as informações relevantes em um único documento, ser livre de esquemas, possuir identificadores únicos universais (UUID), possibilitar a consulta de documentos pelo uso de métodos avançados de agrupamento e filtragem (MapReduce) e também permitir redundância e inconsistência.
Um registro no MongoDB é um documento, que é uma estrutura de dados composta de pares campo e valor. Documentos MongoDB são similares a objetos JSON. Os valores dos campos podem incluir outros documentos, arrays e arrays de documentos.
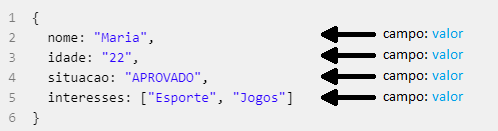
Características:
Apache Cassandra é um banco de dados distribuído NoSQL de código aberto confiável por milhares de empresas para escalabilidade e alta disponibilidade sem comprometer o desempenho. A escalabilidade linear e a tolerância a falhas comprovada em hardware comum ou infraestrutura em nuvem tornam-no a plataforma perfeita para dados de missão crítica.
O Cassandra foi inicialmente desenvolvido pelo Facebook para ser utilizado na busca da caixa de entrada de mensagens. Seu modelo de distribuição do sistema é baseado no Dynamo (desenvolvido pela Amazon) enquanto a forma de organização dos dados é baseado no BigTable (desenvolvido pelo Google).
O Dynamo surgiu a partir da necessidade de um banco de dados simples, altamente escalável e confiável para lidar com grandes demandas de leitura/escrita.
O Big Table também surgiu como uma solução altamente escalável e distribuída, o desafio era armazenar o volume imenso de dados de indexação de todas as páginas web mapeadas pelo Google que é utilizado para alimentar a busca.
Características:
O Redis é um armazenamento de estrutura de dados de chave-valor de código aberto e na memória. O Redis oferece um conjunto de estruturas versáteis de dados na memória que permite a fácil criação de várias aplicações personalizadas.
É o armazenamento de chave-valor mais conhecido atualmente. Ele tem a licença BSD, é escrito em código C otimizado e é compatível com várias linguagens de desenvolvimento. Redis é um acrônimo de REmote DIctionary Server (servidor de dicionário remoto).
Por conta da sua velocidade e facilidade de uso, o Redis é uma escolha em alta demanda para aplicações web e móveis, como também de jogos, tecnologia de anúncios e IoT, que exigem o melhor desempenho do mercado. A AWS oferece compatibilidade com o Redis por meio de um serviço de banco de dados gerenciado e otimizado chamado Amazon ElastiCache for Redis, além de permitir que os clientes executem o Redis autogerenciado no AWS EC2.
Os benefícios proporcionados pelo Redis são:
Casos de uso do Redis:
Flyway é uma ferramenta de migração de banco de dados de código aberto. Favorece fortemente a simplicidade e a convenção sobre a configuração.
É baseado em apenas 7 comandos básicos:
Migrar
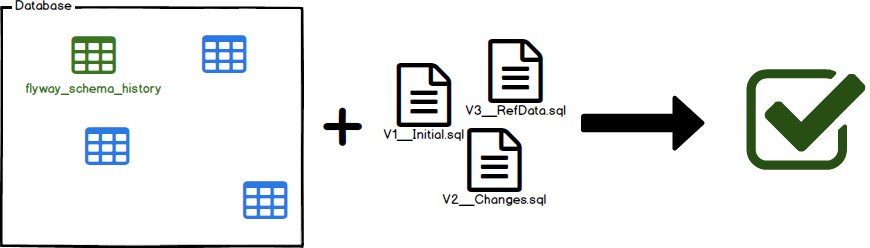
Migrar o esquema para a versão mais recente. O Flyway criará a tabela de histórico de esquema automaticamente se ela não existir.

Ela é a peça central do fluxo de trabalho do Flyway. Ele fará a varredura no sistema de arquivos ou no caminho de classe em busca de migrações disponíveis. Ele os comparará com as migrações que foram aplicadas ao banco de dados. Se alguma diferença for encontrada, ele migrará o banco de dados para fechar a lacuna.
A migração deve ser executado preferencialmente na inicialização do aplicativo para evitar incompatibilidades entre o banco de dados e as expectativas do código.
Limpar
Descarta todos os objetos nos esquemas configurados.
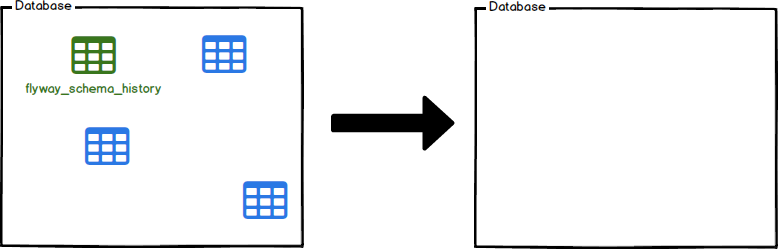
O Clean é uma grande ajuda no desenvolvimento e teste. Ele efetivamente proporcionará a você um novo começo, limpando completamente seus esquemas configurados. Todos os objetos (tabelas, visualizações, procedimentos, …) serão eliminados.
Não use contra seu banco de dados de produção!
Informações
Imprime os detalhes e informações de status sobre todas as migrações.
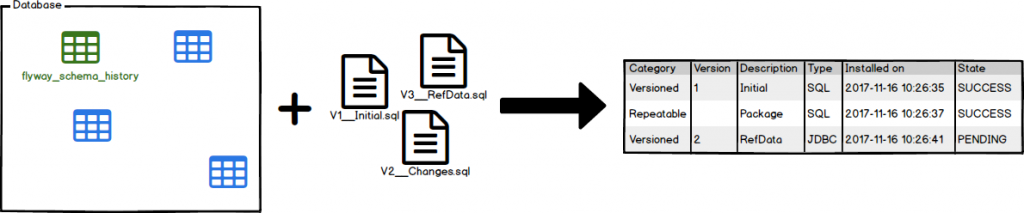
As informações permitem que você saiba onde você está. Você verá rapidamente quais migrações já foram aplicadas, quais outras ainda estão pendentes, quando foram executadas e se foram bem-sucedidas ou não.
Validar
Valida as migrações aplicadas em relação às disponíveis.
Validar ajuda a verificar se as migrações aplicadas ao banco de dados correspondem às disponíveis localmente. Isso é muito útil para detectar alterações acidentais que podem impedir que você recrie o esquema de forma confiável.
Validar funciona armazenando uma soma de verificação (CRC32 para migrações SQL) quando uma migração é executada. O mecanismo de validação verifica se a migração localmente ainda possui a mesma soma de verificação que a migração já executada no banco de dados.
Desfazer
Desfaz a migração com versão aplicada mais recentemente.
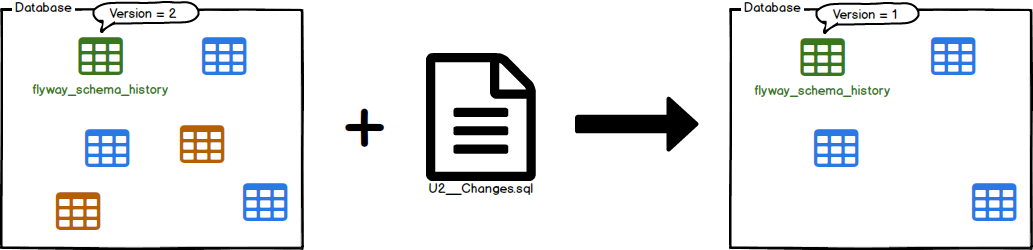
Se o alvo for especificado, o Flyway tentará desfazer as migrações com a versão na ordem em que foram aplicadas até atingir uma com uma versão abaixo do destino. Se o grupo estiver ativo, o Flyway tentará desfazer todas essas migrações em uma única transação. Se não houver migração com versão para desfazer, chamar desfazer não terá efeito.
Linha de base
Limita um banco de dados existente, excluindo todas as migrações até a incluisão da linha de base.
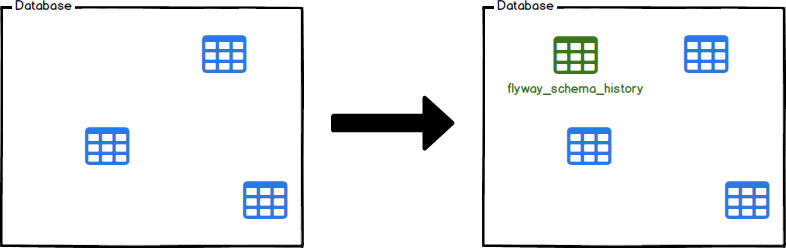
A linha de base é para apresentar o Flyway aos bancos de dados existentes, definindo a linha de base deles em uma versão específica. Isso fará com que o Migrate ignore todas as migrações até a inclusão da versão de linha de base. As migrações mais recentes serão aplicadas normalmente.
Reparar
Repara a tabela de histórico do esquema.
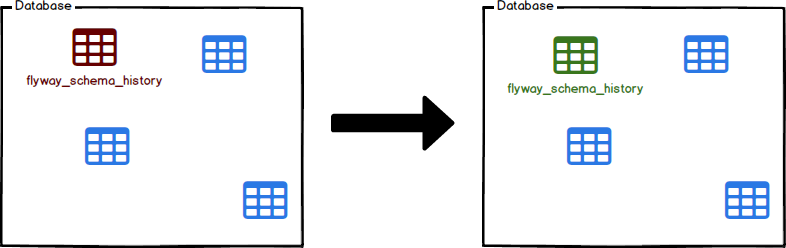
Reparar é uma ferramenta para corrigir problemas com a tabela de histórico do esquema.
Os principais usos são:

Pode-se instalar todos os serviços necessários para manter o banco de dados com alta disponibilidade em uma única VM, mas isso não é uma boa prática já que a ideia é reduzir a dependência de uma só máquina caso essa tenha algum problema e precise ser reiniciada ou desligada.
O ideal é instalar cada serviço necessário em um VM específica (seguindo a arquitetura de servidores da DPMG).
Com base na arquitetura da DPMG, será seguido os seguintes passos:
Atualmente são ofertadas 4 VMs para disponibilização dessa infraestrutura com banco de dados. Partindo dessa premissa vamos para um caso real, segue VMs e seus respectivos serviços que serão necessários instalar e configurar:
Antes de realizar a configuração dos serviços, realize as seguintes configurações:
Faça login na VM e execute o comando:
sudo su
Para alternar para o usuário sudo execute o seguinte para editar o arquivo:
vim /etc/environment**
Edite o arquivo acima e o deixe de acordo com o conteúdo abaixo:
export http_proxy=http://10.100.246.125:3128
export https_proxy=http://10.100.246.125:3128
export ftp_proxy=ftp://10.100.246.125:3128
export no_proxy=localhost,127.0.0.1,10.100.246.*
Para entrar no modo de edição digite:
'i'
Movimente o cursor por meio das setas do teclado. Para sair do modo de edição pressione:
'ESC'
Para salvar e sair digite o comando:
:wq
Vá para home:
cd ~
Clone o projeto server:
git clone http://gitlab.defensoria.mg.def.br/dpmg-ddsp-infra/server.git
Entre na pasta correspondente de acordo com a VM:
server/patroni/prod/'X' -> sendo X o número da VM
Dê permissão para o script:
chmod 777 script.sh
execute o comando:
./
VM: 10.100.246.126
Crie o arquivo com o nome ‘etcd’ sem extensão e com as seguintes configurações. Obs.: substitua os valores referentes ao ip da máquina para a máquina em que será instalado o ETCD.
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_NAME="etcd0"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380,http://0.0.0.0:7001"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.100.246.126:2380, http://localhost:2380"
ETCD_INITIAL_CLUSTER="etcd0=http://10.100.246.126:2380,etcd0=http://localhost:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.100.246.126:2379"
ETCD_INITIAL_CLUSTER_TOKEN="cluster_etcd_10.100.246.126"
Na mesma pasta onde foi criado o arquivo etcd. Execute o seguinte script para instalação e configuração do etcd:
#!/bin/bash
apt-get install etcd -y
systemctl stop etcd
cp etcd /etc/default/etcd
systemctl start etcd
VM: 10.100.246.126
Crie o arquivo com o nome ‘haproxy.cfg’ com o seguinte conteúdo:
yaml
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:9000
stats enable
stats uri /
listen postgres
bind *:5060
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server 10.100.246.127:4433 10.100.246.127:4433 maxconn 100 check port 8008
server 10.100.246.128:4434 10.100.246.128:4434 maxconn 100 check port 8008
server 10.100.246.129:4435 10.100.246.129:4435 maxconn 100 check port 8008
Na mesma pasta onde foi criado o arquivo ‘haproxy.cfg’. Execute o seguinte script para instalação e configuração do haproxy:
#!/bin/bash
apt-get install haproxy -y
systemctl stop haproxy
cp haproxy.cfg /etc/haproxy/haproxy.cfg
systemctl start haproxy
VM: 10.100.246.127
Crie o arquivo de configuração ‘patroni.yml’ :
scope: geralpessoa
name: pg0
restapi:
listen: 0.0.0.0:8008
connect_address: 127.0.0.1:8008
etcd:
host: 10.100.246.126:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
luse_slots: true
parameters:
wal_level: replica
hot_standby: "on"
wal_keep_size: 8
max_wal_senders: 5
max_replication_slots: 5
checkpoint_timeout: 30
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host all postgres all md5
- host replication replicator all md5
- host all all 0.0.0.0/0 md5
- host replication replicator 0.0.0.0/0 md5
- host all postgres 0.0.0.0/0 md5
users:
postgres:
password: senhabd
options:
- createrole
- createdb
replicator:
password: senhabd
options:
- replication
postgresql:
listen: 0.0.0.0:4433
connect_address: 10.100.246.127:4433
data_dir: /data/postgresql
#config_dir: /var/lib/postgresql/data
bin_dir: /usr/lib/postgresql/13/bin
authentication:
replication:
username: replicator
password: senhabd
superuser:
username: postgres
password: senhabd
parameters:
unix_socket_directories: '.'
port: 4433
Crie o arquivo de configuração patroni.service :
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /data/patroni/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=default.targ
Crie o arquivo ‘environment’ :
export http_proxy=http://10.100.246.125:3128
export https_proxy=http://10.100.246.125:3128
export ftp_proxy=ftp://10.100.246.125:3128
export no_proxy=localhost,127.0.0.1,10.100.246.*
Execute o seguinte script:
#atualização proxy
cp environment /etc/environment
#instalação postgresql 13
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get -y install postgresql-13 postgresql-doc-13
systemctl stop postgresql
#instalação PATRONI
sudo apt-get update -y
apt-get install python3 python3-pip -y
pip3 install --upgrade setuptools
pip3 install psycopg2-binary
pip3 install patroni
pip3 install python-etcd
mkdir /data/patroni -p
chown postgres:postgres /data/patroni
chmod -R 700 /data/patroni
mkdir -p /data/postgresql
chown postgres:postgres /data/postgresql
chmod -R 700 /data/postgresql
#copiando arquivos de configuração PATRONI
cp patroni.yml /data/patroni/patroni.yml
#copiando startup script PATRONI
cp patroni.service /etc/systemd/system/patroni.service
systemctl enable patroni
systemctl start patroni
VM: 10.100.246.128
Crie o arquivo de configuração ‘patroni.yml’ :
scope: geralpessoa
name: pg1
restapi:
listen: 0.0.0.0:8008
connect_address: 127.0.0.1:8008
etcd:
host: 10.100.246.126:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
luse_slots: true
parameters:
wal_level: replica
hot_standby: "on"
wal_keep_size: 8
max_wal_senders: 5
max_replication_slots: 5
checkpoint_timeout: 30
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host all postgres all md5
- host replication replicator all md5
- host all all 0.0.0.0/0 md5
- host replication replicator 0.0.0.0/0 md5
- host all postgres 0.0.0.0/0 md5
users:
postgres:
password: senhabd
options:
- createrole
- createdb
replicator:
password: senhabd
options:
- replication
postgresql:
listen: 0.0.0.0:4434
connect_address: 10.100.246.128:4434
data_dir: /data/postgresql
#config_dir: /var/lib/postgresql/data
bin_dir: /usr/lib/postgresql/13/bin
authentication:
replication:
username: replicator
password: senhabd
superuser:
username: postgres
password: senhabd
parameters:
unix_socket_directories: '.'
port: 4434
Crie o arquivo de configuração patroni.service :
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /data/patroni/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=default.targ
Crie o arquivo ‘environment’ :
export http_proxy=http://10.100.246.125:3128
export https_proxy=http://10.100.246.125:3128
export ftp_proxy=ftp://10.100.246.125:3128
export no_proxy=localhost,127.0.0.1,10.100.246.*
Execute o seguinte script:
#!/bin/bash
#atualização proxy
cp environment /etc/environment
#instalação postgresql 13
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get -y install postgresql-13 postgresql-doc-13
systemctl stop postgresql
#instalação PATRONI
sudo apt-get update -y
apt-get install python3 python3-pip -y
pip3 install --upgrade setuptools
pip3 install psycopg2-binary
pip3 install patroni
pip3 install python-etcd
mkdir /data/patroni -p
chown postgres:postgres /data/patroni
chmod -R 700 /data/patroni
mkdir -p /data/postgresql
chown postgres:postgres /data/postgresql
chmod -R 700 /data/postgresql
#copiando arquivos de configuração PATRONI
cp patroni.yml /data/patroni/patroni.yml
#copiando startup script PATRONI
cp patroni.service /etc/systemd/system/patroni.service
systemctl enable patroni
systemctl start patroni
VM: 10.100.246.129
Crie o arquivo de configuração ‘patroni.yml’ :
scope: geralpessoa
name: pg2
restapi:
listen: 0.0.0.0:8008
connect_address: 127.0.0.1:8008
etcd:
host: 10.100.246.126:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
luse_slots: true
parameters:
wal_level: replica
hot_standby: "on"
wal_keep_size: 8
max_wal_senders: 5
max_replication_slots: 5
checkpoint_timeout: 30
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host all postgres all md5
- host replication replicator all md5
- host all all 0.0.0.0/0 md5
- host replication replicator 0.0.0.0/0 md5
- host all postgres 0.0.0.0/0 md5
users:
postgres:
password: senhabd
options:
- createrole
- createdb
replicator:
password: senhabd
options:
- replication
postgresql:
listen: 0.0.0.0:4435
connect_address: 10.100.246.129:4435
data_dir: /data/postgresql
#config_dir: /var/lib/postgresql/data
bin_dir: /usr/lib/postgresql/13/bin
authentication:
replication:
username: replicator
password: senhabd
superuser:
username: postgres
password: senhabd
parameters:
unix_socket_directories: '.'
port: 4435
Crie o arquivo de configuração patroni.service :
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /data/patroni/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=default.targ
Crie o arquivo ‘environment’ :
export http_proxy=http://10.100.246.125:3128
export https_proxy=http://10.100.246.125:3128
export ftp_proxy=ftp://10.100.246.125:3128
export no_proxy=localhost,127.0.0.1,10.100.246.*
Execute o seguinte script:
#!/bin/bash
#atualização proxy
cp environment /etc/environment
#instalação postgresql 13
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get -y install postgresql-13 postgresql-doc-13
systemctl stop postgresql
#instalação PATRONI
sudo apt-get update -y
apt-get install python3 python3-pip -y
pip3 install --upgrade setuptools
pip3 install psycopg2-binary
pip3 install patroni
pip3 install python-etcd
mkdir /data/patroni -p
chown postgres:postgres /data/patroni
chmod -R 700 /data/patroni
mkdir -p /data/postgresql
chown postgres:postgres /data/postgresql
chmod -R 700 /data/postgresql
#copiando arquivos de configuração PATRONI
cp patroni.yml /data/patroni/patroni.yml
#copiando startup script PATRONI
cp patroni.service /etc/systemd/system/patroni.service
systemctl enable patroni
systemctl start patroni
Para mais informações:
Quando um dos nós do PATRONI é o PRIMÁRIO, ou seja, é o utilizado atualmente é exibido o seguinte log em seu console:
Jul 21 17:21:17 vm-spp-db121 patroni[1630876]: 2021-07-21 17:21:17,977 INFO: Lock owner: pg2; I am pg2
Jul 21 17:21:17 vm-spp-db121 patroni[1630876]: 2021-07-21 17:21:17,980 INFO: no action. i am the leader with the lock
Quando um dos nós para e volta, por exemplo, ao reiniciar a VM e já existe um nó PRIMÁRIO é exibido o seguinte log:
Jul 21 17:20:55 vm-spp-db119 patroni[2072298]: 2021-07-21 17:20:55,245 INFO: establishing a new patroni connection to the postgres cluster
Jul 21 17:20:55 vm-spp-db119 patroni[2072298]: 2021-07-21 17:20:55,293 INFO: no action. i am a secondary and i am following a leader
Nexus Repository OSS é um repositório de código aberto que suporta vários formatos de artefatos incluindo Docker, Java e NPM. Com a ferramenta de integração Nexus os pipelines do seu conjunto de ferramentas podem publicar e recuperar suas aplicações versionadas e suas dependências, usando repositórios centrais que são acessíveis por outros ambientes.
**Benefícios: **
**Suporte a todas as ferramentas populares de build: **
O WildFly, que antes se chamava JBoss AS (JBoss Application Server), é um servidor de aplicações open source, escrito em Java, baseado nos padrões definidos pela especificação Java EE e mantido pela comunidade e pela empresa Red Hat (DEVMEDIA, 2020).
Atualmente trabalha-se com a versão WildFly 21 que possui suporte para a especificação Java EE 8 + Jakarta EE 8. É utilizado para prover os serviços backend atráves de APIs rest. Possui integração com Apache ActiveMQ.
O Apache Camel é uma estrutura de integração de código aberto versátil baseada em padrões de integração mais conhecidas.
O Camel permite definir regras de roteamento e mediação em uma variedade de linguagens específicas de domínio, incluindo uma API Fluent baseada em Java, arquivos de configuração Spring ou Blueprint XML. Possibilitando assim o preenchimento inteligente das regras de roteamento em sua IDE, seja em um editor Java ou XML.
Em um alto nível, Camel consiste em um CamelContext que contém uma coleção de instâncias de Component. Um Component é essencialmente uma fábrica de instâncias de Endpoint. Você pode configurar explicitamente as instâncias do Component em código Java ou um contêiner IoC como Spring, ou eles podem ser descobertos automaticamente usando URIs.
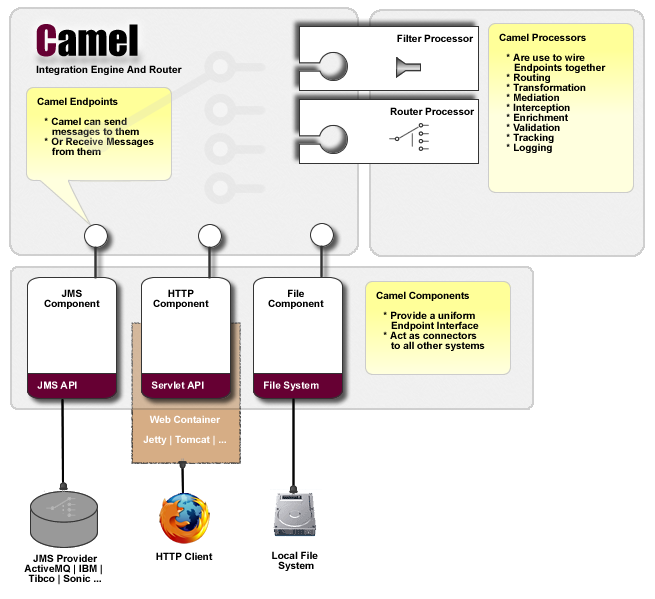
O WildFly Camel fornece a integração do Apache Camel com o WildFly Application Server.
O subsistema WildFly-Camel permite adicionar Camel Routes como parte da configuração do WildFly. As rotas podem ser implantadas como parte de aplicativos JavaEE. Os componentes JavaEE podem acessar a API Camel Core e várias APIs de componentes Camel. Possibilitando que a solução de integração corporativa possa ser arquitetada como uma combinação das funcionalidades JavaEE e Camel.
O NGINX é um famoso software de servidor web de código aberto. Em sua versão inicial, funcionava para a veiculação da Web HTTP. Hoje, no entanto, também serve como proxy reverso, balanceador de carga HTTP e proxy de e-mail para IMAP, POP3 e SMTP. O projeto, criado em 2002, tinha como expectativa responder ao problema C10k — o desafio de gerenciar dez mil conexões ao mesmo tempo.
Hoje, há ainda mais conexões com as quais os servidores da Web precisam lidar. Por esse motivo, o Nginx oferece uma arquitetura baseada no fluxo de tarefas. Esse recurso o torna um dos servidores mais confiáveis em termos de velocidade e escalabilidade. Devido à sua excelente capacidade de lidar com muitas conexões, vários sites de alto tráfego têm usado o serviço da NGINX. Alguns desses gigantes online são Google, Netflix, Adobe, Cloudflare, WordPress.com e muitos outros.
O NGINX consome menos memória que o Apache, pois lida com requisições Web do tipo “event-based web server” enquanto o Apache é baseado no “process-based server”. É trabalhar com ambos ao mesmo tempo de tal forma que seja possível diminuir o consumo de memória do Apache, passando as requisições Web primeiro no Nginx. Dessa forma, o Apache não precisa servir arquivos estáticos, e pode depender do bom controle de cache feito pelo Nginx.
O Nginx foi projetado desde o início para usar um algoritmo de tratamento de conexão sem bloqueio e orientado a eventos. Ele gera processos de trabalho, nos quais é possível manipular milhares de conexões. Esses processos, por sua vez, implementam um mecanismo de loop rápido, que faz uma verificação contínua e processa eventos.
Cada uma das conexões é colocada no loop de eventos no qual elas existem com outras conexões. Dentro do loop, os eventos são processados de forma assíncrona, permitindo que o trabalho seja tratado de maneira não bloqueante. Quando a conexão é fechada, ela é removida do loop. Esse estilo de processamento de conexão permite que o Nginx seja extremamente eficaz, mesmo com recursos limitados. Como o servidor é de encadeamento único e os processos não são gerados para lidar com cada nova conexão, a memória e o uso da CPU tendem a permanecer relativamente consistentes, mesmo em momentos de carga pesada.
O Nginx foi desenvolvido como forma de disponibilizar um baixo uso de memória, além de uma alta simultaneidade. Ele trabalha de forma que as solicitações sejam tratadas em um único thread. Isso evita que o servidor crie processos para cada solicitação.
Node.js é um ambiente de execução JavaScript assíncrono orientado a eventos, dessa forma, ele é projetado para desenvolvimento de aplicações escaláveis em rede. A arquitetura Node.js fornece flexibilidade e baixo custo o tornando uma boa alternativa para implementar microsserviços e componentes da arquitetura Servless. Os usuários Node.js não precisam se preocupar com deadlocks de processo e quase nenhuma função no Node.js realiza operações E/S, sendo assim, o processo nunca bloqueia. Como não existem operações bloqueantes, sistemas escaláveis são razoavelmente fáceis de serem desenvolvidos em Node.js.
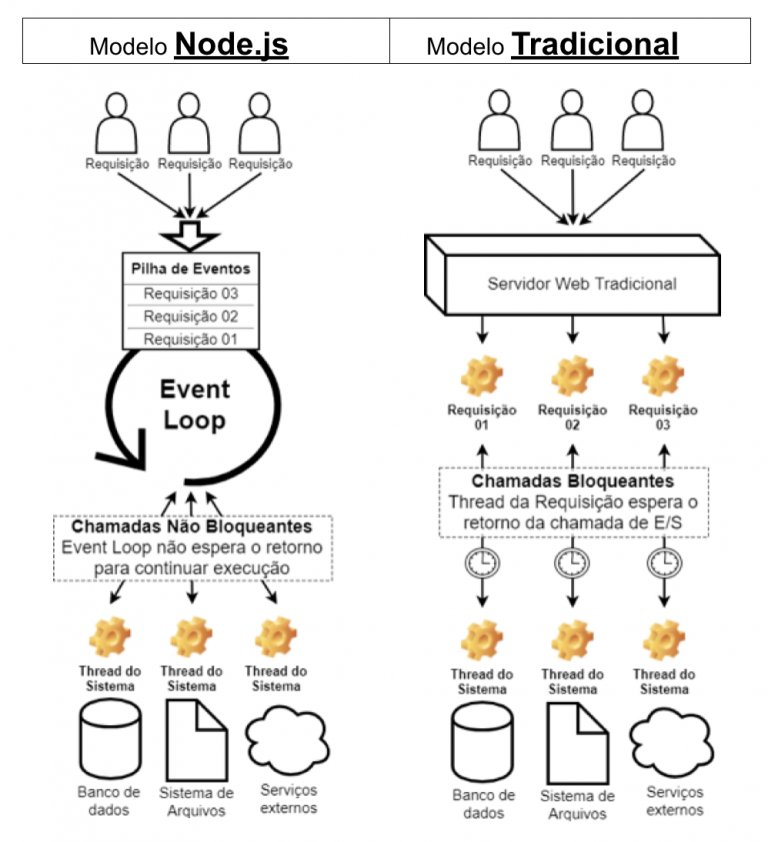
**Utilidades mais comuns: **
O GitLab Runner é um aplicativo, de código aberto, que funciona com o GitLab CI/CD para
executar tarefas para qual foi designado. O principal objetivo do GitLab Runner é a automatização de
processos
Geralmente é utilizado para:
O Git é um sistema de controle de versões distribuído, usado principalmente no desenvolvimento de software.
Cada diretório de trabalho do Git é um repositório com um histórico completo e habilidade total de acompanhamento das revisões, não dependente de acesso a uma rede ou a um servidor central.
Configurando sua auditoria no Git
No git existem configurações que permitem definir seu nome de usuário e seu e-mail, que aparecerão
nos commits do repositório remoto, seja ele um repositório pessoal ou corporativo.
Sendo assim, é importante que seu nome de usuário e e-mail sejam correspondentes aos que foram
definidos para sua conta do repositório remoto da DDSP.
A autoria permite saber quem exatamente fez cada commit, e como dito, suas credenciais devem ser as mesmas que as configuradas no repositório remoto. Para manter a organização em sua área de trabalho, separando seus projetos pessoais dos destinados ao trabalho, poderão ser criados gitconfigs individuais.
Criando gitconfig individual
Para isso, é recomendado que seja criada uma pasta destinada apenas aos projetos da DDSP.
Crie uma pasta para os projetos da Defensoria
mkdir ~/Documents/projetos-DDSP/Crie um arquivo na pasta que foi destinada para o armazenamento dos projetos
No Linux
cd ~/Documents/projetos-DDSP/
touch .gitconfigNo Windows
cd ~/Documents/projetos-DDSP/
ni .gitconfigNo do arquivo “.gitconfig” especifique seu nome de usuário e e-mail que foram utilizados para criar sua conta no [repositório remoto]:
[user]
name = Seu Nome # Nome que está no endereço de e-mail
email = seuemail@defensoria.mg.def.brInclua as configurações no gitconfig global, no arquivo que está localizado no diretório local do seu usuário (~/.gitconfig)
[includeIf "gitdir:~/Documents/projetos-DDSP/"]
path = ~/Documents/projetos-DDSP/.gitconfigO GitLab é um gerenciador de repositório de software baseado em GIT, com suporte a Wiki, gerenciamento de tarefas e CI/CD. Ele é software livre, distribuído pela Licença MIT.
O Docker é uma plataforma open source que facilita a criação e administração de ambientes isolados. Ele possibilita o empacotamento de uma aplicação ou ambiente dentro de um container, se tornando portátil para qualquer outro host que contenha o Docker instalado (TREINAWEB, 2021).
Então, você consegue criar, implantar, copiar e migrar de um ambiente para outro com maior flexibilidade. A ideia do Docker é subir apenas uma máquina, ao invés de várias. E, nessa única máquina, você pode rodar várias aplicações sem que haja conflitos entre elas (TREINAWEB, 2021).
Como ele funciona?
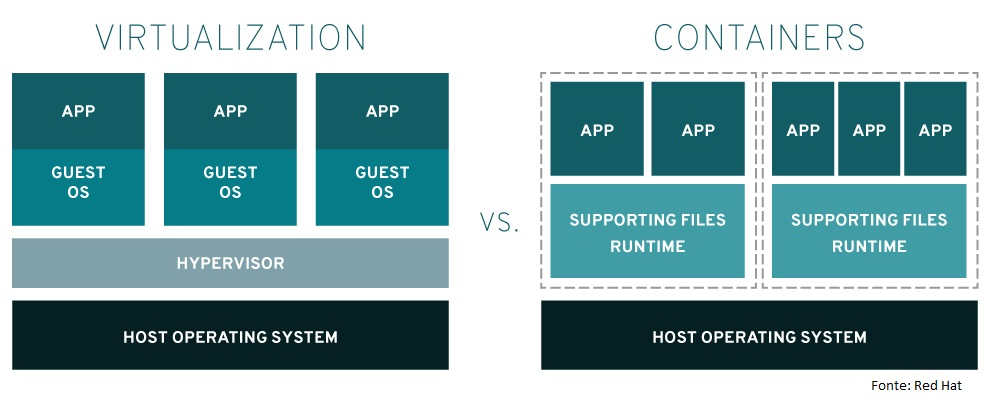
O Docker utiliza o modelo de container para “empacotar” a aplicação que, após ser transformada em imagem Docker, pode ser reproduzida em plataforma de qualquer porte.
Os containers são isolados a nível de disco, memória, processamento e rede. Essa separação permite grande flexibilidade, onde ambientes distintos podem coexistir no mesmo host, sem causar qualquer problema. Vale salientar que o overhead nesse processo é o mínimo necessário, pois cada container normalmente carrega apenas um processo, que é aquele responsável pela entrega do serviço desejado. Em todo caso, esse container também carrega todos os arquivos necessários (configuração, biblioteca e afins) para execução completamente isolada (STACK.DESENVOLVEDOR.EXPERT, 2021).
**Quais são os benefícios do Docker? **
Configuração e disponibilização de serviços isoladamente.
As imagens são compostas por várias camadas.
Um container é o local onde estão as modificações da aplicação que está em execução.
O Dockerfile e o DockerCompose traduzem para uma linguagem em comum a configuração do ambiente para a disponibilização de serviços. A disponibilização é realizada através de poucos comandos.
Na DPMG atualmente utilizamos o Python na versão 3.11.7 e o Powershell na versão 10.0.1, essas linguagens de programação são utilizadas para realizar manutenções, automações, backup e restore de algumas aplicações, além de ser usadas esporadicamente para realizarmos mudanças em massa nos nomes de arquivos.

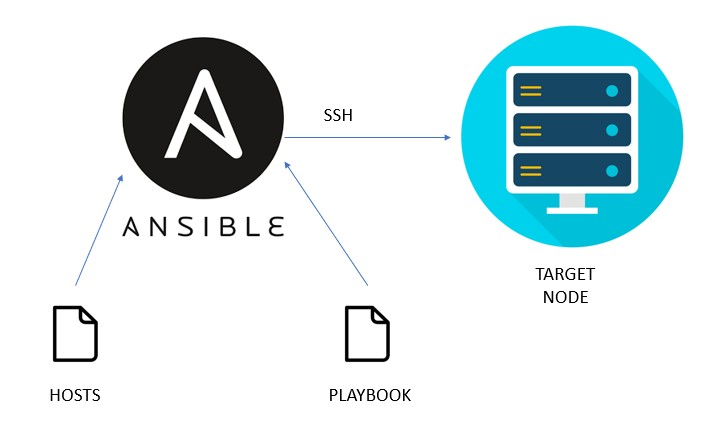
Para gerenciar e padronizar o ambiente de servidores da DPMG atualmente utilizamos o Ansible na versão 2.9.6, ferramenta essa que serve para provisionar configurações em massa e de forma automática em nossos serviços como por exemplo o cluster Patroni, ajustes ou criação de usuários em servidores Linux, renovação de certificados SSL dentre outros.
Fluxo Ansible
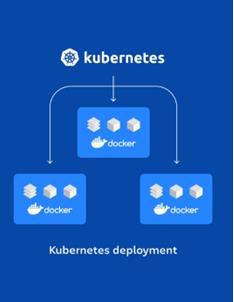
No cenário atual da defensoria trabalhamos com o conceito de micro serviço, esses micros serviços são vários containers que estão configurados em vários servidores distintos. Para realizar a gerencias desse grande número de containers, utilizamos uma ferramenta chamada Kubernets, com ela conseguimos orquestrar de forma menos complexa, ágil e pratica o grande número de containers que utilizamos, desde o deploy da aplicação até o rollback. Atualmente estamos utilizando o Kubernets na versão 1.23.6.
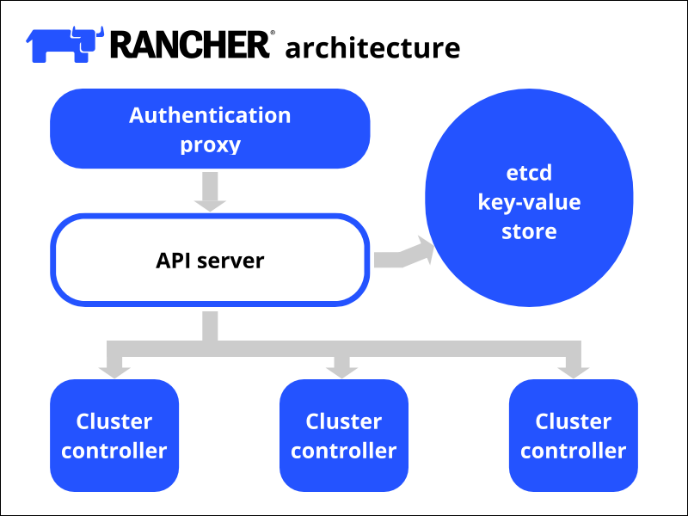
Para gerenciar todos os nós do cluster Kubernets utilizamos o gerenciador Rancher. O Rancher é uma ferramenta que tem como objetivo administrar uma infraestrutura em Docker e Kubernets, a versão utilizada do Rancher pela infraestrutura defensoria é a 2.6.5.
“ELK” é o acrônimo para três projetos open source: Elasticsearch, Logstash e Kibana.
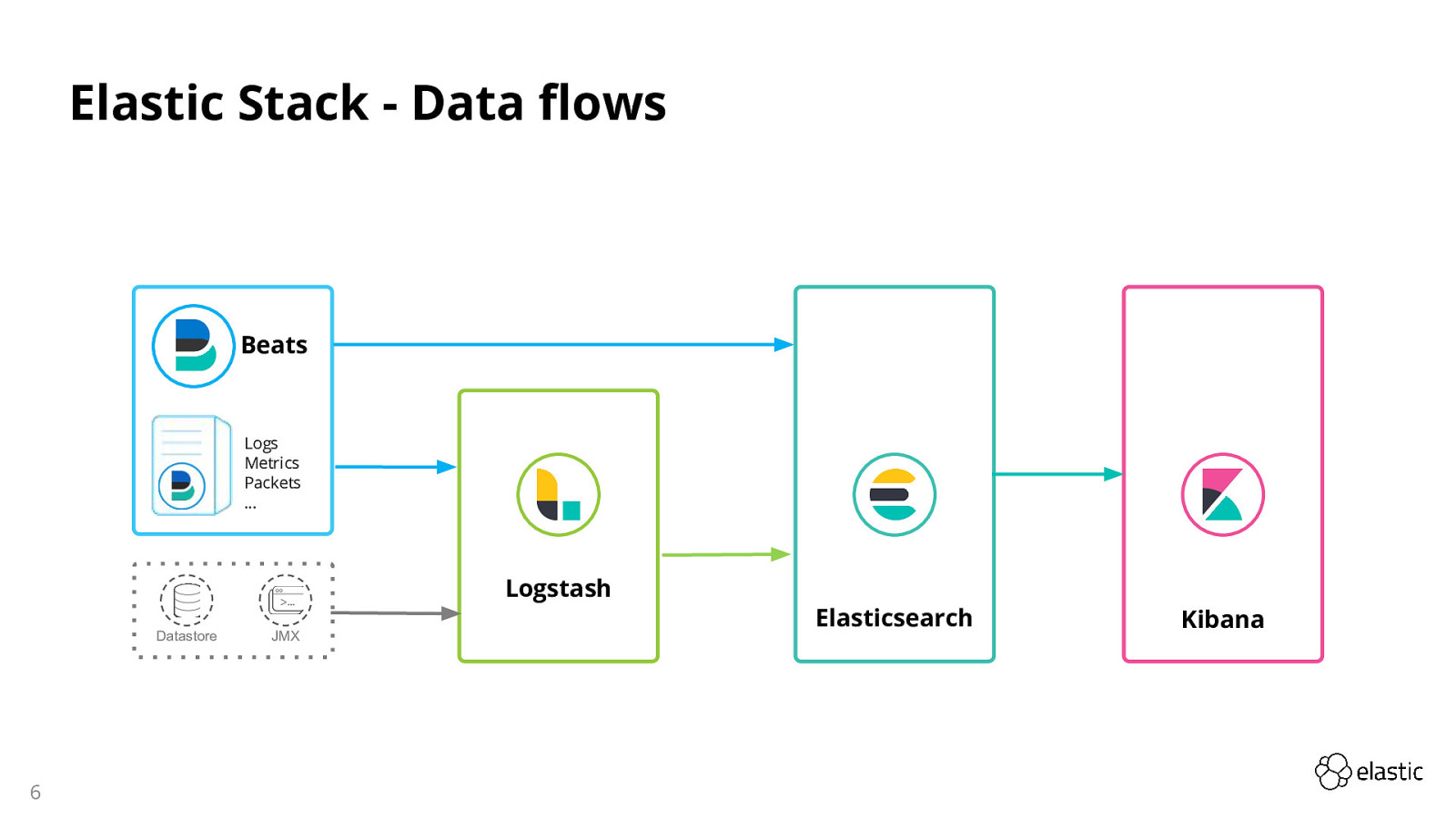
Elasticsearch é um poderoso motor de busca desenvolvido em cima do Apache Lucene (uma das bibliotecas de busca textual mais importantes do mercado). O Elasticsearch é um mecanismo de análise de dados e busca RESTful distribuído baseado em JSON. Possui integração com as tecnologias Java, .NET (C#), PHP, Python, Apache Groovy, Ruby, entre outras.
O Logstash é um pipeline gratuito e aberto de processamento de dados do lado do servidor que faz a ingestão de dados de inúmeras fontes, transformando-os e enviando-os para o seu “esconderijo” favorito.
Os dados com frequência estão dispersos ou isolados em muitos sistemas e em muitos formatos. O Logstash oferece suporte a uma variedade de entradas que importa eventos de inúmeras fontes comuns, tudo ao mesmo tempo. Faça a análise e gestão descomplicada de logs, métricas, aplicativos web, armazenamentos de dados e vários serviços da AWS, tudo em um fluxo contínuo.
Os pipelines do Logstash geralmente possuem múltipla finalidade e podem se tornar sofisticados, tornando assim imprescindível um sólido entendimento do desempenho dos pipelines, da disponibilidade e dos gargalos. Com os recursos de monitoramento e de visualização do pipeline, você pode observar e estudar facilmente um nó ativo do Logstash ou até mesmo uma implantação total.
À medida que os dados trafegam da fonte ao armazenamento, os filtros do Logstash analisam cada evento, identificam campos nomeados para desenvolver a estrutura e os transformam para convergirem em um formato comum para proporcionar uma análise mais poderosa e com mais valor para os negócios.
O Logstash transforma e prepara dinamicamente os dados, independentemente do formato ou da complexidade:
As possibilidades são infinitas com a nossa avançada biblioteca de filtros e o versátil Elastic Common Schema.
O Kibana é uma aplicação gratuita e aberta de front-end que trabalha com o Elastic Stack, fornecendo recursos de busca e visualização de dados indexados no Elasticsearch. Comumente conhecido como a ferramenta de gráficos para o Elastic Stack (que anteriormente chamava-se ELK Stack após o Elasticsearch, o Logstash e o Kibana), o Kibana também atua como interface do usuário para monitorar, gerenciar e proteger um cluster do Elastic Stack, além de ser o hub centralizado para soluções integradas desenvolvidas no Elastic Stack. Desenvolvido em 2013 a partir da comunidade do Elasticsearch, o Kibana cresceu e se tornou a janela de acesso ao próprio Elastic Stack, oferecendo um portal para usuários e empresas.
Com o Kibana é possível:
Kibana é para administradores, analistas e usuários de negócio. Trabalha com todos os tipos de dados. O núcleo do Kibana fornece os recursos clássicos: histogramas, gráficos de linha, gráficos de pizza, explosão solar e muitos outros. E, evidentemente, você pode buscar por todos os documentos.
O Filebeat é um log shipper pertencente à família Beats, que chama a atenção pela praticidade de configuração e pela pequena quantidade de recursos de sistema que consome. Na prática ele funciona como um agente de envio de logs para um serviço de coleta de logs qualquer. Como o próprio nome indica, é dedicado ao envio de arquivos de log.
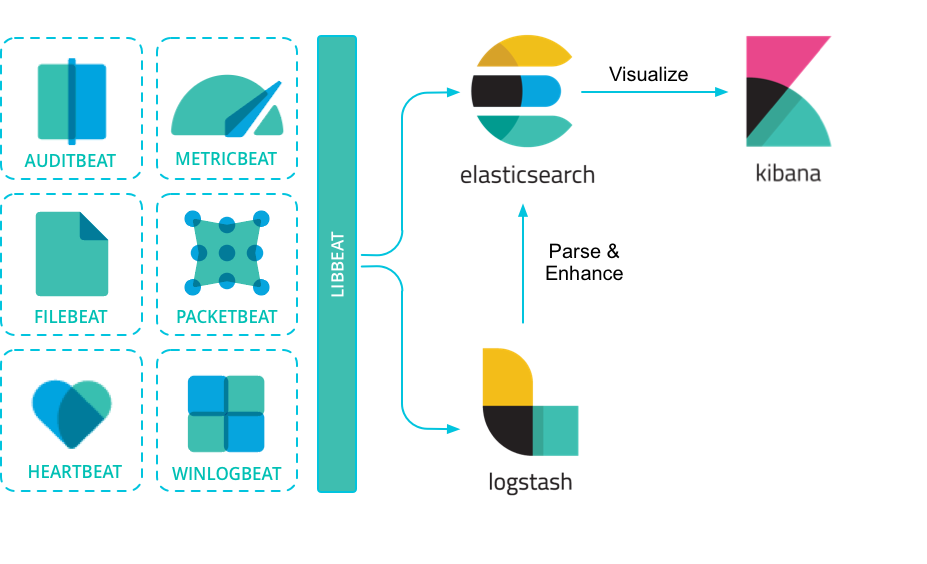
Em um pipeline de registro, baseado no ELK, o Filebeat desempenha o papel de agente de registro – instalado na máquina gerando arquivos de registro, acompanhando-os e encaminhando para o Logstash para um processamento mais avançado ou diretamente para o Elasticsearch para indexação. Filebeat, portanto, não é um substituto para o Logstash, mas sim, algo que pode e deve ser usado em conjunto na maioria dos casos.
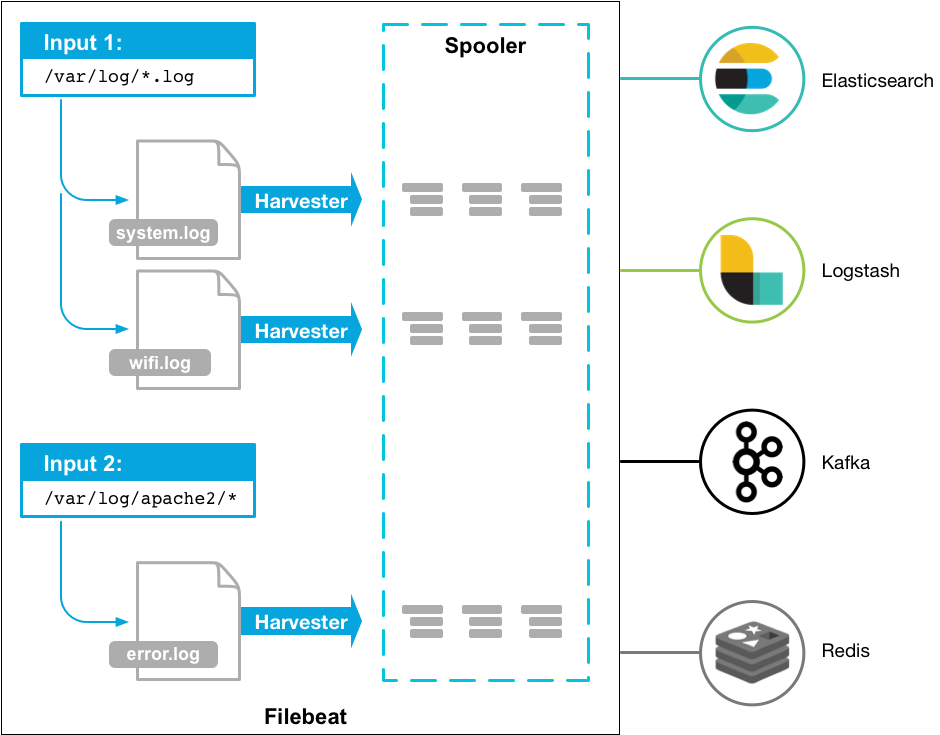
Características:
O aplicativo Uptime no Kibana possibilita monitorar o status dos endpoints na rede via HTTP/S, TCP, e ICMP mostrando a disponibilidade e o tempo de resposta das aplicações e serviços em tempo real com o objetivo de detectar problemas antes de afetar os usuários. Você pode explorar o status dos endpoints ao longo do tempo, aprofundar em monitores específicos e ter uma visão geral do seu ecossistema em momentos específicos.
[IMG – UPTIME]
A primeira versão do Heartbeat, lançado inicialmente em versão beta em janeiro de 2017, é um shipper lightweight — bem parecida com o restante dos outros Beats (Metricbeat, Filebeat, Winlogbeat etc.) — mas foi projetado para monitorar o funcionamento.
O Heartbeat executa verificações periódicas para conferir se o endpoint está ativo ou inativo, e relata essas informações, juntamente com outras métricas úteis, ao Elasticsearch. Essas informações são exibidas automaticamente em dashboards pré-criados do Kibana para permitir o monitoramento de tempo de funcionamento completo. O Heartbeat pode operar de dentro ou de fora da rede. Basta ele ter acesso da rede ao endpoint HTTP, TCP ou ICMP desejado. A configuração é tão simples quanto fornecer ao Heartbeat a lista de URLs que se deseja monitorar.
A combinação de dados do Heartbeat com fontes de dados adicionais como Metricbeat, Filebeat e APM pode fornecer informações importantes ao fazer triagem de uma pane. O Heartbeat notificará quando um serviço específico estiver inativo; o Metricbeat e o APM podem apresentar os possíveis suspeitos; podem melhorar significativamente o MTTR e farão com que cada um olhe para o lugar certo, em vez de ficar “apontando o culpado”.
Alertas de detecção de anomalias:
É possível usar os recursos de alertas para obter alertas e notificações sobre uma falha ou uma queda na performance com base nos dados de monitores do Heartbeat. Os recursos de Machine Learning do Elastic Stack também podem ser usados para detectar quaisquer anomalias com base na análise de dados de séries de tempo dos dados do Heartbeat.
Os utilitários são ferramentas adicionais, e não obrigatórias, utilizadas pela equipe da Defensoria Pública de Minas Gerais para auxiliar em atividades específicas.
Google Chrome é um navegador livre desenvolvido pela Google, empresa multinacional de serviços online e software dos Estados Unidos.
Mozilla Firefox é um navegador livre e multiplataforma desenvolvido pela Mozilla Foundation. Esse utilitário é utilizado para o acesso e desenvolvimento das aplicações WEB dentro da Defensoria Pública de Minas Gerais (DPMG).
Cmder (se pronuncia “Commander”) é um pacote de software pré-configurado que provê para o usuário um emulador de terminal e um excelente shell para o Windows. Foi criado justamente pela ausência de um emulador console utilizável no Windows. Ele é baseado no ConEmu com grande revisão de configuração, esquema de cores Monokai, incrível clink para fornecer um prompt do tipo bash usando a linha de leitura do GNU, e um layout de prompt personalizado.
A principal vantagem do Cmder é a portabilidade. Ele é projetado para ser totalmente independente, sem a necessidade de dependências externas, o que o torna um ótimo dispositivos USB ou armazenamento em nuvem. Assim, você pode carregar seu console, aliases e binários (como wget, curl e git) com você em qualquer lugar.
Com o Cmder você terá todas as facilidades de copiar e colar, e também poderá usar os comandos do Prompt de Comando do Windows ou do seu compatível Linux, é isso mesmo! Tudo na mesma janela de comando, portanto, use o que for mais familiar.
OpenVPN é um daemon VPN de código aberto que tem como objetivo ser uma ferramenta VPN universal oferecendo grande flexibilidade na utilização, suporte à segurança SSL / TLS, ponte de ethernet, transporte de túnel TCP ou UDP por proxies ou NAT, suporte para endereços IP dinâmicos e DHCP, escalabilidade para centenas ou milhares de usuários e portabilidade para a maioria das principais plataformas de sistema operacional.
O OpenVPN está estreitamente ligado à biblioteca OpenSSL e possui muito dos recursos de criptografia partindo dela. Também suporta criptografia mais convencional usando uma chave secreta pré compartilhada (modo de chave estática) ou segurança de chave pública (modo SSL / TLS) usando certificados de cliente e servidor. Além de oferecer suporte a túneis TCP / UDP não criptografados.
Microsoft Teams é uma plataforma criada para promover a colaboração e interação em tempo real, permitindo aos usuários conversas individuais, em grupos, reuniões por vídeo chamada, compartilhamento de anexos e anotações e colaboração de conteúdo com os aplicativos Microsoft 365 integrando fluxos de trabalho e aplicativos essenciais para a empresa.
Gerenciamento: é possível gerenciar os dispositivos dos trabalhadores remotos na nuvem com configurações de segurança, aplicativos permitidos e exigir conformidade com a integridade do sistema.
Produtos:
O Notepad ++ é um editor de código-fonte gratuito e um substituto do Notepad que suporta vários idiomas. Rodando no Windows, seu uso é regido pela GNU General Public License.
Baseado no poderoso componente de edição Scintilla, o Notepad ++ é escrito em C ++ e usa Win32 API e STL puras, o que garante maior velocidade de execução e menor tamanho do programa. Ao otimizar o máximo de rotinas possíveis sem perder a facilidade de uso, o Notepad ++ está tentando reduzir as emissões mundiais de dióxido de carbono. Ao usar menos energia da CPU, o PC pode desacelerar e reduzir o consumo de energia, resultando em um ambiente mais verde.
Notepad++ suporta as linguagens: C, C++, Java, C#, XML, HTML, PHP, JavaScript, makefile, ASCII art, doxygen, ASP, VB/VBScript, Unix Shell Script, BAT, SQL, Objective-C, CSS, Pascal, Perl, Python, Lua, Tcl, Assembly, Ruby, Lisp, Scheme, Smalltalk, PostScript e VHDL. Além disto, usuários podem definir suas próprias linguagens usando um “sistema de definição de linguagem” integrado, que faz do Notepad++ extensível, para ter realce de sintaxe e compactação de trechos de código.
Ele suporta autocomplemento, busca e substituição com integração de expressões regulares, divisão de tela, zoom, favoritos, etc. Tem suporte para macros e plugins. Um plugin de usuário chamado TextFX, que provê opções de transformação de textos, é incluído por padrão.
“O Postman é um API Client que facilita aos desenvolvedores criar, compartilhar, testar e documentar APIs. Isso é feito, permitindo aos usuários criar e salvar solicitações HTTP e HTTPs simples e complexas, bem como ler suas respostas.
Além da praticidade de ter todos os exemplos e códigos de integração prontos, o POSTMAN é a ferramenta oficial de teste pelas equipes de desenvolvimento e suporte. Dessa maneira ao realizar integrações, caso você possua dúvidas, será mais rápido e simples de confirmar o que pode estar ocorrendo com o seu código.
Outras vantagens do Postman:
Cliente FTP FileZilla funciona de forma independente de plataforma e suporta sistemas operacionais como Microsoft Windows(Vista ou Superior), GNU / Linux, * BSD e Mac OS X. É de fácil utilização, compatível com FTP, FTP SSL/TLS (FTPS) e com protocolo de transferência de arquivos SSH (SFTP), possui suporte a IPv6, a transferência de arquivos grandes maiores que 4GB, consegue gerenciar localmente uma fila grande de transferência, implementa o Drag and Drop, proporciona a configuração do limite de velocidade de transferência, possibilita comparação de diretórios e edição de arquivos online com editores de textos.
O WinSCP é um cliente de FTP, para Windows, que garante transferências seguras sobre SSL, de forma que os arquivos FTP não sejam interceptados por terceiros. A chave do programa é o fato de que ele suporta também SFTP e SCP protocolos por SSH-1 e SSH-2. WinSCP não é o mais fácil cliente de FTP que existe.
Características:
Git Bash é um utilitário para ambientes do Microsoft Windows que fornece a camada de emulação para a experiência de linha de comando Git, ele possui as operações da experiência Bash padrão. Bash é acrônico para “Bourne Again Shell”. Shells são aplicativos terminais usados como interface em sistemas operacionais por meio de comandos gravados. O Shell é o padrão popular no Linux e no macOS. O Git Bash é o pacote que instala o Bash, alguns utilitários de bash comuns e o Git nos sistemas operacionais Windows.
O git bash faz parte do pacote Git para Windows, é possível baixá-lo e instalá-lo como todos outros aplicativos.
Git GUI
Como usuários Windows comumente esperam uma interface gráfica, Git para Windows também fornece Git GUI, uma poderosa alternativa para o Git BASH, oferecendo uma versão gráfica sobre cada função de linha de comando Git, bem como ferramentas de comparação visual abrangentes.
O Photoshop, é o software de imagem digital mais avançado do mundo, usado por fotógrafos, designers, profissionais da web e de vídeo. O aplicativo dá a você máximo poder e controle criativo para manipulação e composição de imagens 2D e 3D, edição de vídeo e análise de imagem.
O Illustrator é uma ferramenta de design capaz de desenvolver ilustrações. Além disso, é possível também editar imagens vetoriais já prontas.
Ela é muito usada na confecção de logos, por exemplo, além de todo aspecto vetorial de sites, campanhas e material impresso. No caso de animações, o ideal é produzir a ilustração no Illustrator e, depois, enviá-la para um outro programa como o After Effects — também da Adobe.
Axure RP Pro / Team é um software para a criação de protótipos e especificações para sites e aplicativos. Ele oferece posicionamento de arrastar e soltar, redimensionamento e formatação de widgets. Características O Axure RP oferece suporte à prototipagem de aplicativos da Web ricos , mapeando os comportamentos de interface desejados (como exibir ou ocultar um elemento) em resposta a ações como cliques do mouse ou gestos de toque. O Axure RP gera sites HTML para visualização e colaboração em equipe, bem como documentos do Microsoft Word como saída para documentação de produção. O Axure RP também pode se conectar a outras ferramentas e serviços, como Slack e Microsoft Teams, para colaborar. O Axure RP também pode se ajustar automaticamente e mover-se suavemente do macOS para o Windows. Por segurança, os protótipos podem ser enviados com proteções de senha para garantir a divulgação completa. Os usuários criam controles personalizados combinando widgets existentes e atribuindo ações em resposta a eventos como OnClick, OnMouseOver e OnMouseOut ou gestos de toque como beliscar e deslizar. Por exemplo, os painéis de interface podem ter vários estados, cada um sendo ativado clicando em um elemento, como um botão de guia, item da caixa de listagem ou botão de ação.
Existem três versões: Pro, Team e Enterprise. O produto Pro está disponível gratuitamente para alunos e professores, e com descontos para instituições de ensino. A versão Pro adiciona recursos de documentação, incluindo controle de layout, saída para Microsoft Word e Excel e suporte para projetos de equipe.
Sparx Systems Enterprise Architect é uma ferramenta de modelagem e design visual baseada na OMG UML . A plataforma suporta: o projeto e construção de sistemas de software; modelagem de processos de negócios; e modelagem de domínios baseados na indústria.
A modelagem de sistemas usando UML fornece uma base para modelar todos os aspectos da arquitetura organizacional, junto com a capacidade de fornecer uma base para projetar e implementar novos sistemas ou alterar sistemas existentes. Os aspectos que podem ser cobertos por este tipo de modelagem variam desde o layout de arquiteturas organizacionais ou de sistemas, reengenharia de processos de negócios , análise de negócios e arquiteturas orientadas a serviços e modelagem da web, até aplicativos e design de banco de dados e re -engenharia e desenvolvimento de sistemas embarcados. Junto com a modelagem do sistema, o Enterprise Architect cobre os principais aspectos do ciclo de vida de desenvolvimento de aplicativos, desde o gerenciamento de requisitos até as fases de projeto, construção, teste e manutenção, com suporte para rastreabilidade, gerenciamento de projetos e controle de alterações desses processos, bem como, facilidades para o desenvolvimento orientado a modelos de código de aplicação usando uma plataforma de desenvolvimento integrado interno .
A seguir estão os principais padrões suportados:
UML 2.5 SysML 1.5 BPMN 2.0 DMN BMM MARTE 1.2 BPEL SoaML SPEM WSDL XSD DDS ArchiMate 3.0 ArcGIS IFML CMMN Linguagem de marcação de geografia (GML) ODM , OWL e RDF VDML 1.0
Os recursos comuns de gerenciamento de requisitos suportados pelo Enterprise Architect incluem customização de como os requisitos são documentados, vinculando os requisitos aos detalhes de design e implementação e fornecendo rastreabilidade de requisitos durante as fases de design e construção. Esses requisitos podem estar sujeitos a gerenciamento de mudanças, processamento de fluxo de trabalho, comparação de linha de base e auditoria.
O Enterprise Architect oferece suporte a vários métodos de modelagem de processos de negócios usando UML como a linguagem de modelagem básica. As linguagens principais para modelagem e análise de negócios incluem BPMN , BMM e VDML , junto com vários perfis históricos.
O Enterprise Architect suporta a simulação de: Modelos BPMN usando BPSim Definições de regras de negócios usando modelos DMN . BPMN pode ser integrado com modelos DMN para simulação. Isso inclui a capacidade de gerar código executável a partir dessas regras de negócios. A modelagem de negócios pode ser combinada com a análise de lacunas para visualizar lacunas potenciais nas soluções propostas.
A simulação de modelo é compatível com diagramas comportamentais, incluindo: máquinas de estado, interação (diagramas de sequência) e diagramas de atividades. Para máquinas de estado e diagramas de atividades, o fluxo de execução é definido usando gatilhos, guardas e efeitos. A simulação suporta reexecuções com alteração dos eventos disparados e suporta a visualização de variáveis, a pilha de chamadas e a configuração de marcadores de depuração. A simulação pode interagir com telas de interface de usuário emuladas contendo campos de IU comuns. Plots gráficos da simulação podem ser gerados. Também há suporte para geração de código executável a partir de State Machines tanto para simulação, quanto para uso em aplicativos. Modelos BPMN (usando BPSim) podem ser simulados criando resultados tabulados para análise. O BPSim também suporta simulações baseadas em probabilidade de Monte Carlo. A simulação SysML é suportada para modelos IBD e Paramétricos usando Open Modelica ou Matlab (usando Simulink e Simscape). Fórmulas matemáticas nos diagramas de bloco interno e modelos paramétricos do SysML podem ser simuladas para gráficos de plotagem usados na análise. A simulação também é compatível com DMN ( modelo de decisão e notação ). A simulação envolve a geração de código utilizável em aplicativos e suporta a interação entre modelos DMN e modelos BPMN usando BPSim.
Em linha com os princípios de design orientado por modelo, o Enterprise Architect suporta transformações MDA de estruturas de classe PIM em estruturas de classe PSM , engenharia de código para dez linguagens de software e várias linguagens de sistemas HDL incorporados ( Ada , VHDL e Verilog ). Ele também oferece suporte à geração de código a partir de modelos comportamentais. As linguagens suportadas incluem ActionScript , C , C # e C ++ , Delphi . Java , PHP , Python , Visual Basic e Visual Basic .NET De acordo com os princípios de desenvolvimento orientados por modelo, o Enterprise Architect fornece um ambiente de desenvolvimento integrado que suporta edição de código (com destaque de sintaxe e Intellisense ), para construção, depuração e teste de código, tudo dentro do modelo. Compiladores e interpretadores suportados: Microsoft Windows Native C, C ++, Visual Basic, família .NET (C #, VB); Compiladores Java, PHP e GNU para C ++, C e Ada ( GCC e GDB ). Inclui recursos para importar projetos MS Visual Studio e Eclipse .
A modelagem em wireframe oferece suporte ao uso de modelos para modelar a aparência dos diálogos apresentados aos usuários ao interagir com um aplicativo. Os diálogos de dispositivos suportados incluem: Diálogos de tela, páginas da Web, telefones e tablets Android, Apple e Windows 8.1.
Para teste baseado em código, há suporte para ambos os testes xUnit (isso envolve a transformação MDA de classes em classes NUnit ou Junit com a capacidade de gerar testes de unidade a partir do modelo e registrar automaticamente os resultados em relação às classes testadas) e teste de ponto de teste (um teste de código baseado em modelo. É paralelo aos contratos de teste definidos em ‘Design by Contract’ e é executado usando definições de depuração. Ambos os métodos suportam as definições de teste e os resultados do teste sendo registrados em classes relacionadas no modelo.
Integrado com o código de construção e depuração, o Enterprise Architect permite ao desenvolvedor realizar análises abstratas do software usando criação de perfil e geração de diagramas de sequência: a geração de diagramas de sequência fornece um meio de analisar o fluxo de processo geral e resolver inconsistências, e o Profiling resume, por thread e rotina, a eficiência geral do código.
A engenharia de sistema é suportada com modelagem SysML 1.4, que pode ser acoplada à geração de código executável. O SysML oferece suporte à modelagem desde a definição de requisitos e composição do sistema usando blocos e peças SysML até a simulação de modelo paramétrico. A geração de código executável suporta linguagens de sistema HDL embutidas ( Ada , VHDL e Verilog ), ou pode ser acoplada à geração de código comportamental das linguagens de código padrão definidas acima.
O Enterprise Architect suporta modelagem de dados do nível conceitual para o físico, engenharia direta e reversa de esquemas de banco de dados, e transformação MDA do DBMS lógico (independente da plataforma) para o físico (dependente da plataforma). Os tipos de diagrama suportados incluem: notação DDL, notação ERD , notação IDEF1X , notação de Engenharia da Informação. DBMSs com suporte incluem: DB2 , Firebird / InterBase, MS Access 97, 2000, 2003, 2007, 2013, MS SQL Server , todas as edições de 2005, incluindo Express e Azure, MySQL , MariaDB , SQLite , Oracle from 9i (todas as edições), PostgreSQL , ArcGIS , Informix , Ingres , Sybase Adaptive Server Anywhere (Sybase ASA) e Sybase Adaptive Server Enterprise (Sybase ASE).
Os recursos de suporte ao gerenciamento de projetos incluem: Alocação e rastreamento de recursos usando gráficos de Gantt , diagramas Kanban, registro de eventos usando calendários modelo, script de fluxo de trabalho para definir processos de fluxo de trabalho, segurança e métricas de modelo. Os principais recursos de suporte ao gerenciamento de mudanças são: auditoria, diferença e fusão de linha de base e controle de versão. A interface de controle de versão suporta os principais aplicativos de controle de versão: Subversion , CVS , Team Foundation Server e interface SCC para qualquer sistema de controle de versão compatível com SCC.
Os recursos que oferecem suporte à integração com outras ferramentas incluem: XMI Import / Export: Suporta as especificações XMI 1.1, 1.2 e 2.1 (e importação de arquivos .emx e Rhapsody), Open Services for Lifecycle Collaboration (OSLC), CSV Import / Export, ArchiMate Open Importação / Exportação do Formato do Exchange. O Pro Cloud Server Integration suporta a integração de dados de fornecedores externos, incluindo Application Lifecycle Management, Jazz (DOORS, Rhapsody DM, Team Concert CCM e QM), Jira, Confluence, TFS, Wrike, ServiceNow, Autodesk, Bugzilla, Salesforce e SharePoint. O Data Miner fornece um meio de extrair dados de uma variedade de fontes de dados externas, incluindo: bancos de dados (ODBC, ADO, OLEDB, JET), arquivos de texto (XML, JSON, texto simples), Excel (xls, CSV) e arquivos online ou URLs. A interface de automação – oferece suporte a uma API abrangente para uso com qualquer linguagem baseada em COM (e Java). Isso oferece suporte à definição de scripts internos, bem como acessibilidade para escrever suplementos externos. Também há suporte para suplementos orientados a eventos baseados em modelo usando Javascript. Entre os suplementos disponíveis estão interfaces para Microsoft Office e DOORS, junto com suplementos de terceiros.